导读
日拱一卒,功不唐捐,分享是最好的学习,一个知识领域里的 “道 法 术 器” 这四个境界需要从 微观、中观以及宏观 三个角度来把握。微观是实践,中观讲套路,宏观靠领悟。本系列文章我把它命名为《分布式系统架构设计三十六式》,讲诉分布式系统里最重要的三十六个虚数的中观套路,而微服务的本质也是分布式,因此搞明白这三十六个最重要的知识点也就同时能搞明白微服务。
实现一个分布式系统通常会面临三大难题: 故障传播性、业务拆分与聚合以及分布式事务 。本系列中的服务治理章节主要是为了解决故障传播性的难题,它包括: 隔离、熔断、降级、限流、容错以及资源管控-系统自适应算法 ,本文将讲述服务治理里的 “系统自适应模式” 模式。
动机
分布式系统的灵魂 :从产品思维的角度来看,好的产品都是有自己灵魂的。比如微信的产品灵魂被定位成“善良”,善有大善、上善、小善。《道德经》有言:“上善若水,水善利万物而不争,处众人之所恶(wù),故几于道。”,水善利万物而不与万物争,水无处不在,万物感觉不到水的存在又离不开水,不争故天下莫能与之争。每种好的产品背后都隐藏着自己的设计哲学,有自己的灵魂。而一个分布式系统的灵魂又应该怎么定义呢?认知层次不同,对分布式系统的理解也不同,度量一个分布式系统的灵魂,在我看来可以采用分布式系统的SLO图形指标来表达。好的分布式系统SLO指标也是很有规律很漂亮的,如下图所示,左图波形上跳下串,很明显不如右边波形来的漂亮。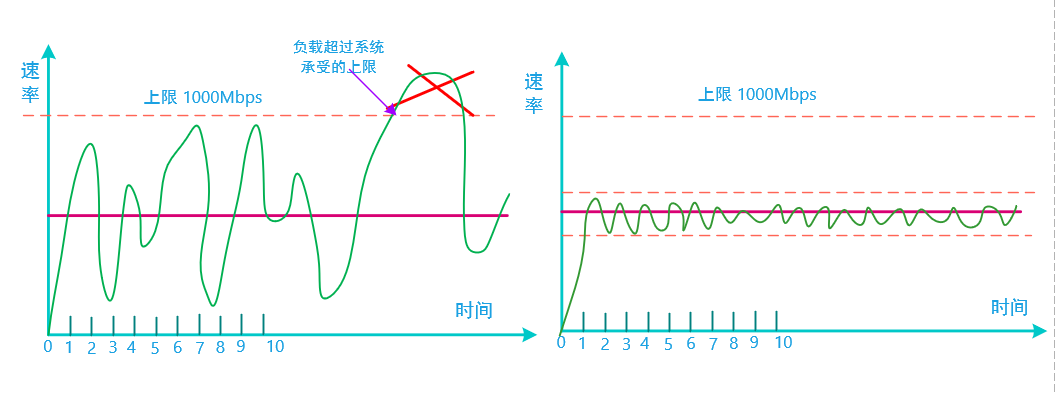
波形上跳下串带来的后果是什么呢?想象一下在高速路开车的场景,如果一辆车一会快,一会慢,后面的车会发生什么事?这样开车是很容易出事故的,而开得很稳的车出故障的概率就较小。波形上跳下串,说明该系统里头没有解决好资源竞用性以及服务治理的问题。
可靠性与高性能的平衡 :我们知道要让一个水管里的水流的又快又多,一是给水管灌满水,二是水管通畅同时保证不炸裂水管。同样的道理,在分布式系统里要让系统跑出最好的性能和最可靠的效果,一方面压榨整个系统的资源,另一方面又要保证系统不出故障,在系统不出故障的前提下,尽量榨尽系统资源。
因此为了解决以上问题,这里提出了系统自适应模式。
系统自适应模式设计思路
资源平衡
服务治理与其说是分布式下的套路,不如说是控制论下的套路,其本质是资源的细粒度管控,精巧的平衡整个系统里的资源竞用,从而保证分布式系统对外提供高质量的服务。如下图《一根羽毛的力量》所示,其将平衡的思想用到极致,我们也希望在分布式系统里体现有限资源下的平衡。

我们将平衡的思想融入分布式系统,在系统健康的前提下,极致的压榨系统的能力(capacity),同时又保证不会主动造成系统故障,如果发现系统内部出现故障,又会自动调整下发的压力,这就是系统自适应保护。
最佳衡量指标
如何确定最佳的衡量指标?通常比较的原始情况下,是以工作负载比如1分钟、5分钟、15分钟的CPU负载作为系统衡量指标,但是这并不大正确。比如假设 CPU load > 2 就 触发一个系统保护,如果这个 时候系统的CPU load是在下降的,它虽然此时刻大于2, 但是趋势却是下降,因此没必要触发系统保护。还有就是干扰性,比如 按 1分钟负载&& 5分钟负载&&15分钟负载,全都是满足大于2的条件就触发系统保护。但是实际上,也许 5分钟负载是不大于2的,因此这个条件就不成立,并不会触发系统过载保护, 这种行为我称之为负载干扰性。
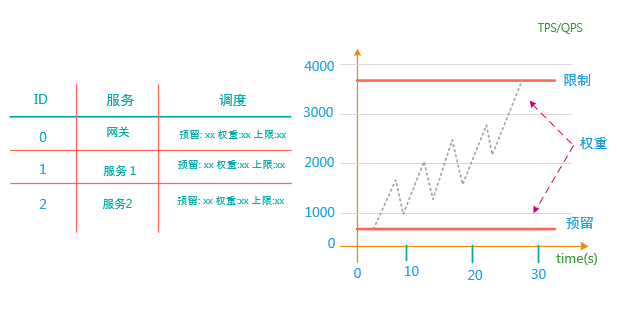
参考水管的流量算法只依赖于管的截面大小以及流速,我们定义系统的自适应算法依赖的参数为系统入口处的 QPS或TPS ,以及请求的返回时间(RT),这里我将这个公式定义为 System Balance Capacity = QPS * RT。
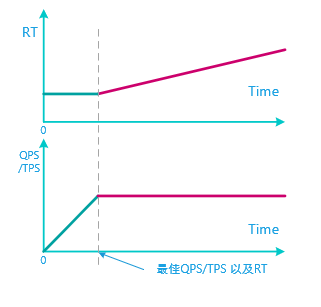
如上图,最好的情况就是即满足 最大的QPS 又满足最小的RT,通过一个时间窗口计算QPS 和 RT ,自适应调整整个系统。
系统自适应算法
下图表示了一个自适应算法,造成系统负载过高以及故障传播的因素很多,比如不合适的线程数、TPS或QPS过大、返回时间过长都有可能,通过合适的算法可以自动调整下发的压力从而保持系统的内部资源平衡。
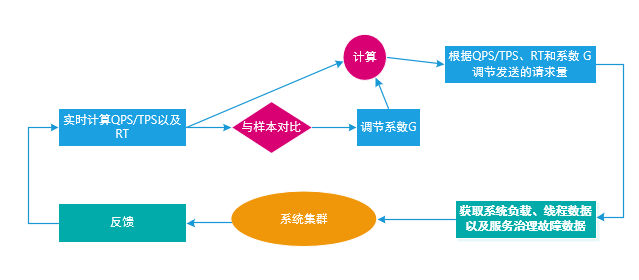
通过采用系统自适应算法在系统的入口处,实时采集QPS/TPS 以及RT, 然后跟最佳样本值进行比较,依据调节系数进行计算,再调节发送的请求量,发送请求后又采集造成的影响,再反馈在系统入口处。其中,样本值可以在系统启动时按动态采样的方式计算,逐渐增加QPS ,当发现时延发生转折时,我们就确定这个转折点为分布式系统自适应最佳平衡点,记下该值作为当前样本。
小结
本文讲诉了服务治理里的 “系统自适应”模式,在前一篇《分布式系统架构设计三十六式之服务治理-5F容错模式》里讲诉了分布式系统服务治理的容错模式。另作者能力与认知都有限,欢迎大家拍砖留念。
作者简介
常平,中科大硕,10年+数据相关经验,主要工作背景为分布式系统、存储、缓存、微服务、云计算以及大数据,现就职于DELL EMC。个人技术博客:https://changping.me
版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh ,可以自由阅读、分享、转发、复制、分发等,限制是需署名、非商业使用(以获利为准)以及禁止演绎。