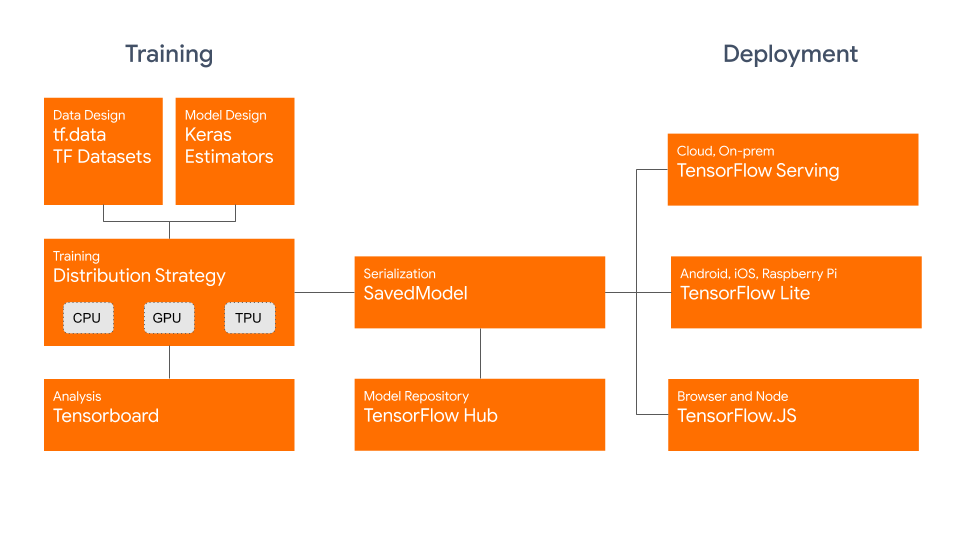
前言
本文的动机在于应用物理学思维模型破解分布式系统背后不变的本质,并以此解读分布式系统里的各种算法设计、功能设计以及非功能设计。在“分布式系统” 这个词语里,关键词可以分为“分布式”及“系统”,而“系统 = 要素 + 连接 + 目标”,在这个公式里,要素的变化不会影响系统的本质,而“连接或目标”的变化就会改变系统的本质,其中“分布式”是系统的连接方式,挖掘分布式系统背后的本质即是挖掘“分布式系统”的要素、连接以及目标的本质。
物理学的价值观在于追求所有物理现象背后的共同的底层规律,并以此解读各种物理现象,并且其具有“可解释、可重复、可预测”的可度量性,这种共同的底层规律,被称之为元认知,即第一性原理:“任何变化的背后都有不变的本质”。将这种思维模型应用于挖掘分布式系统的本质,需要解决两个问题,即:“ 什么是分布式系统的第一性原理?以及如何度量分布式系统?”
分布式系统的价值与目的
分布式系统的出现是为了解决一个主要矛盾,即:“日益增长的数据计算、传输与存储的需求与当前单点计算机能力无法满足这个需求之间的矛盾”。分布式系统可以通过伸展集群规模解决这个矛盾,因此这就是分布式系统的价值,而可伸缩性(Scalability,避免与可扩展性extensibility混淆)也是分布式系统的根本目的。
分布式系统必知的基础理论与算法
分布式系统必须理解、必须会的基础理论算法有:CAP/PACELC、BASE、2PC、3PC、TCC、ACID、PAXOS、RAFT这9个:
- CAP: CAP理论认为以下三者不能同时满足:
- 一致性(Consistency): 所有的节点在同一时刻数据是完全一样的;
- 可用性(Availability): 节点失效不会影响系统的IO;
- 分区容忍性(Partition Tolerance): 系统能支持网络分区(网络连接故障),即使分区之间的消息丢失系统也正常工作。
- PACELC: PACELC理论是CAP理论的扩展,如果有分区partition (P),系统就必须在availability 和consistency (A and C)之间取得平衡; 否则else (E) 当系统运行在无分区情况下,系统需要在 latency (L) 和 consistency (C)之间取得平衡”;
- BASE: BASE是基本可用(Basically Available)、软状态(Soft state)和最终一致性(Eventually consistent)三个短语的缩写;
- 2PC:two-phase commit protocol,两阶段提交;
- 3PC: three-phase commit protocol ,三阶段提交,其在两阶段提交的基础上增加了CanCommit阶段,并引入了超时机制;
- TCC: Try-Confirm-Cancel,又称补偿事务,其核心思想是:”针对每个操作都要注册一个与其对应的确认和补偿(撤销操作)”;
- ACID: 原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durablity);
- PAXOS/RAFT :PAXOS与RAFT算法都是最有效的解决分布式一致性问题的算法。
这几条基础理论与算法需要自己深入学习理解,其是分布式系统的必备知识点。
分布式系统的功能与非功能
功能
功能可按职责划分为服务功能与算法功能:
- 分布式系统里的最主要的服务功能有:服务提供,服务注册,服务配置,服务调用、服务路由、服务治理设计,服务观测、服务安全这8项;
- 分布式系统里的最主要的算法功能有:幂等性设计、事务算法设计、端到端的校验算法设计、路由算法设计、分区分配算法设计、集群视图变更算法设计、心跳算法设计、注册算法设计、复制一致性算法设计以及容量规划算法设计。
非功能
非功能可划分为质量与约束:
质量是分布式系统在约束条件下的度量方式,其涵盖:合适的性能(Performant)、可用性(Availability)、可靠性(Reliability)、可伸缩性(Scalability)、韧性(resilience)、可观测性(Observability)、安全性(security)、易用性(usability)、可运维性(operability)、可测试性(testability)、可维护性(maintainability)、可扩展性(extensibility)、可读性(readability)等。
约束是分布式系统的资源限制:网络物理容量与计算机节点的物理容量,以及客户、用户、团队的边界约束。
分布式系统交付的目的是功能的价值,但是产品的功夫却体现在非功能,分布式系统的质量是分布式系统的度量方式,分布式系统要可度量就需要具有“可解释、可复制、可预测”的质量保证。
分布式系统的第一性原理
依据李善友老师的定义: “第一性原理思维 = 逻辑奇点 + 公理化方法 ”,逻辑奇点即基石假设,公理化方法我认为是”定公理、推定理、再公式化应用”。因此欲找出分布式系统的第一性原理,就需要先挖掘出分布式系统的公理化定义及其逻辑奇点。
首先把分布式系统概念化,Google 出来的对分布式系统的定义有:
1 | |
即:
分布式系统是指其组件位于不同的网络计算机上的系统,这些组件通过相互传递消息来进行通信和协调其动作,且彼此相互交互以完成一个共同的任务目标。
拆解这句话,从中可以看到分布式系统里的要素即为组件,连接即网络,目标是共同的任务,并且还可以看出4个要点:
分布式系统的组件是位于不同的网络计算机上;
分布式系统的组件通过传递消息进行通信其动作;
分布式系统的组件通过传递消息进行协调其动作;
分布式系统的组件是通过相互交互以完成一个共同的任务目标;
其中最最重要的可以看作是分布式系统的基石假设的要点是:
1,分布式系统的组件是位于不同的网络计算机上;
2,这些组件通过相互传递消息来进行通信和协调其动作,且彼此相互交互以完成一个共同的任务目标。
这两点即为分布式系统的逻辑奇点,破除了这两点那就不是分布式系统,比如去掉网络计算机的定义,那就是单机系统,去掉协调以完成共同的任务目标,那就只是一个计算机网络。这两点基石假设构成分布式系统的逻辑奇点。
到此,可以得出分布式系统的公理化定义:
分布式系统是指其组件位于不同的网络计算机上的系统,这些组件通过相互传递消息来进行通信和协调其动作,且彼此相互交互以完成一个共同的任务目标。
以及分布式系统的逻辑起点:
分布式系统是指其组件位于不同的网络计算机上的系统:即计算机网络;
这些组件通过相互传递消息来进行通信和协调其动作,且彼此相互交互以完成一个共同的任务目标:即协同:“谐调一致,和合共同,协调两个或者两个以上的不同资源或者个体,一致地完成某一共同目标”;
再进一步抽象,可以推断出“分布式系统就是通过计算机网络进行协同工作的系统”, 至此,可以推出分布式的公理化定义公式:
1 | |
这个公式就是分布式的第一性原理公式,是分布式的本质理论定义,其中“计算机”是分布式系统的要素,“网络”是分布式系统的连接,“协同”是分布式系统的目标,从这公式里可以看出分布式系统的3个原生的难题:
分布式系统是基于网络的系统,那么网络自身所具有的所有的优点与缺点它都有,那么如何提高服务的可靠性?如何保证服务的可用性?如何保证网络可运维?
分布式系统是基于消息传递的系统,消息传递是不可靠的,那么如何保证消息的正确性?如何保证消息传递的可靠性?如何传递消息到目的地?如何保证消息传递的负载均衡?
分布式系统是协同工作的系统,那么如何协调大量的计算机节点的完成一个共同的目标,如何解决协调的复杂性以及提高协调的可靠性、可用性?那么如何一起交互完成一个共同的目标任务?如何拆分目标?如何聚合目标,如何度量完成任务的质量与边界?
因此还需要依据分布式系统的公理化定义推导出定理化定义。
分布式系统的定理化推导
“公理是不证自明的,而定理是以若干的公理或其他定理为基础而推导的”。由公理推定理,从分布式的公理化公式“分布式系统 = 计算机 + 网络 + 协同”,可知分布式系统是组件位于“不同的计算机网络”上一起“协同”工作的系统,这句话得出分布式系统三要素:“计算机、网络,协同”。其中计算机是系统要素,改变计算机为虚机或者容器,不会改变分布式系统的本质。网络是系统的连接,改变连接就会改变系统的本质,当连接一台计算机时,就是单机,当连接两台计算机时就是镜像,当连接 多于两台计算机时就是分布式。协同是系统的目标,当改变协同的目标也就改变了系统的功能,比如共同计算与共同存储、共同调度,其功能目标是不一样的。
计算机
分布式系统是基于不同的计算机上的系统,计算机也是分布式系统的要素之一,因此分布式系统也继承了计算机的原生缺点,
- 计算机节点是会出故障的,主板、CPU、网卡、硬盘、内存、电源等都会出故障,比如老化、失效等;
- 计算机节点内的操作系统是会突然奔溃不能提供服务的;
- 计算机节点是会突然掉电的;
- 计算机节点里的内存下电是不保数据的;
- 计算机节点的资源是有限的:CPU是有算力上限的、内存是有大小限制的、网卡有吞吐量限制、硬盘有空间大小限制以及速率限制;
这几个计算机的原生缺点意味着分布式系统需要能够知道计算机节点是失效的,以及在计算机节点失效的同时保证服务质量设计,那么就应当进行以下几点保证:
可观测性(observability)设计:监控、告警、日志、追踪;
可靠性(Reliability)设计:冗余设计、分区分配设计、复制算法设计、幂等性设计、一致性算法设计;
容量(capacity)规划设计:计算机节点资源资源有限,就需要分布式系统进行进行容量规划;
服务治理(Service governance)设计:CPU算力有限、内存有限、网卡吞吐量有限、磁盘IO有限,因此需要进行服务治理之隔板设计以及限流、限并发设计。
网络
分布式系统是基于不同的网络上的系统,网络是分布式系统的连接方式之一,连接一台计算机的系统就是单机系统,连接两台计算机的系统就是镜像系统,连接三台及以上数目的计算机的系统就是分布式系统,因此分布式系统也继承了网络的原生缺点,即:
- 网络是不可靠的;
- 网络是会出故障的;
- 网络是有时延的;
- 网络是会抖动的;
- 网络是不安全的;
- 网络是会丢包的;
- 网络是有带宽限制的;
- 网络消息是会乱序的;
由此,为了保证分布式系统的服务质量:性能、可用性、可靠性、安全性等,那么就需要进行服务质量保证设计,其可以划分为:
网络是不可靠以及会出现断网之类的故障的,因此分布式系统需要进行服务治理容错设计;
网络乱序以及丢包,因此分布式系统需要幂等性算法设计、端到端的校验算法设计;
网络带宽有限,因此分布式系统需要网络容量设计以及服务治理限流设计;
网络不安全:因此分布式系统需要服务安全设计;
网络是有时延的,因此分布式系统需要进行性能设计:更好的硬件、跟短的IO路径;
网络是会抖动的,因此分布式系统需要进行服务治理容错之超时处理设计。
协同
协同是指:“谐调一致,和合共同,协调两个或者两个以上的不同资源或者个体,一致地完成某一共同目标“,这些组件通过相互传递消息来进行通信和协调其动作,且彼此相互交互以完成一个共同的任务目标
协同又可以拆分为协调动作与共同完成任务,即:
协调动作
分布式系统的组件通过传递消息进行通信及协调其动作,即:因此依据消息传递的特性以及缺点需要进行相应的协调动作设计:
- 传递消息特性意味着需要进行RPC调用设计;
- 网络里传递的消息是经常不一样的,因此需要序列化编解码设计;
- 消息传递具有丢消息、丢处理的弊端,为了解决这个弊端就需要进行 :幂等性设计、事务处理设计、日志设计;
- 消息的传递是会超时的,因此就需要服务治理容错之超时处理设计;
- 消息是基于网络传输的,而网络是可能随时出故障的,因此需要对消息进行可观测性设计即消息追踪设计;
- 需要知道消息从哪里来,往哪里去就需要一个配置中心管理集群各个计算机的信息,比如IP,因此需要进行配置中心设计;
- 光知道可以发往哪里还不够,还要知道发往的节点是活着的可服务的,需要知道计算机节点的服务状态,还需要保证消息路由的负载均衡,因此这就就需要一个协调的服务注册中心,进行服务组件的注册与心跳检测、消息路由以及按集群视图变更算法管理集群状态表,那么就需要注册中心设计、注册算法设计、负载均衡算法设计,心跳算法设计、集群视图变更算法设计以及集群状态表管理设计。
共同完成任务
分布式系统的组件是通过相互交互以完成一个共同的任务目标,因此需要解决共同完成任务并且保证任务完成质量带来的难题:
整个分布式系统需要能接收任务以及返回完成的任务,那么就需要有提供服务的能力,需要有服务调用接口设计,服务调用客户端以及可视化界面;
为了能让网络里的N台计算机相互交互完成一个共同的目标,就需要对任务进行拆分以及聚合设计;
- 任务拆分后要能知道发给哪个节点,那么就需要一个配置中心, 从配置中心获取目标节点信息;
- 任务拆分后分发给节点同时要保证处理的性能,那么就需要进行可伸缩性设计,一台机器处理不过来就需要N台机器一起处理从而保证处理的性能质量,因此又衍生出需要路由算法设计或分区分配算法设计,这样拆分后的任务可以被分发到不同的独立的节点进行处理,并且,但一个节点不可用时,还可以分发到其他的可用的节点,从而提升了系统性能与可用性;
- 任务又可以分为计算任务与存储任务,如果是存储任务,为了保证数据的可用性以及可靠性,就需要对分区进行冗余设计,即节点副本设计,如果需要节点副本设计又引入了选主算法设计、数据一致性复制算法设计与幂等性设计;
- 为了解决选主与复制一致性问题,又出现了PAXOS,RAFT,2PC,3PC 等,这样的基础一致性协议算法。
至此,依据分布式的公理化公式:“分布式系统 = 计算机 + 网络 + 协同”,推导出了分布式的定理化推论,解读了分布式系统里为什么需要进行这些功能与非功能设计的问题,接下来还需要讲述分布式系统的度量。
分布式系统的度量
分布式系统是依据分布式公理定义的质量进行度量的,其涵盖以下几项内容:
合适的性能(Performant),性能指标一般包括 TPS, QPS, Latency, IOPS, response time等,这里用”合适的性能“作为表达,指的是性能合适即可、够用即可,高性能当然好,但是高性能也意味着更高的成本,有些场景高性能反而是一种浪费行为,性能需求需要理解业务场景适可而止;
可用性(Availability),可用性指的是系统长时间可对外提供服务的能力,通常采用小数点后的9的个数作为度量指标,按照这种约定“五个九”等于0.99999(或99.999%)的可用性,默认企业级达标的可用性为6个9。但是当前从时间维度来度量可用性已经没有太大的意义,因为设计得好的系统可以在系统出现故障得情况下也能保证对外提供得服务不中断,因此,当前更合适得可用性度量指标 是请求失败率;
可靠性(Reliability),可靠性一般指系统在一定时间内、在一定条件下可以无故障地执行指定功能的能力或可能性, 也是采用小数点后的9的个数作为度量指标,通常5个9的可靠性就可以满足企业级达标;
可伸缩性(Scalability),是指通过向系统添加资源来处理越来越多的工作并且维持高质量服务的能力,其受可用性以及可靠性的制约,集群规模越大出故障的概率越高从而降低可用性、可靠性,为了保证可用性以及可靠性达标,需要适配合理的可伸缩性指标;
韧性(resilience),通常也叫容错性(fault-tolerant),也就是健壮和强壮的意思,指的是系统的对故障与异常的处理能力,比如在软件故障、硬件故障、认为故障这样的场景下,系统还能保持正常工作的能力;
可观测性(Observability),是一种设计理念,包括告警、监控、日志与跟踪,可以实时地更深入地观测系统内部的工作状态;
安全性(security),指的是阻止非授权使用,阻止非法访问以及使用,保护合法用户的资产的能力;
易用性(usability),指的是软件的使用难易程度,对于产品的易用性来说, 易用性不仅仅 是软件使用角度的易用,还包括安装、部署、升级上的易用,升值还包括硬件层面的易用,比如产品的外观,形状等;
可运维性(operability),可运维性指的是运维人员对系统进行运维操作的难易程度,主要包含以下几个方面的难以程度: 系统的部署、升级、修改、监控以及告警等;
- 可测试性( testability),指的是单元测试,集成测试,打桩测试等的难易;
- 可维护性(Maintainability), 指的是代码升级,部署,定位bug,添加功能的难易;
- 可扩展性( extensibility), 指的是未来增加新的功能与模块的难易;
可读性( readability),指的是代码的易理解程度。
边界约束:集群规模、计算机的容量等物理资源的限制,以及客户、用户、团队的约束需求。
依据这几项质量度量指标,可以保证分布式的“可解释、可复制、可预测”。其中要保证质量的核心思想是“共享资源、消除资源竞用性以及平衡负载。”,共享资源需要注册中心,消除资源竞用性就需要服务治理,平衡负载需要好的路由算法。
分布式系统的反熵增与数据守恒
熵增
熵增定律是物理学的基本定律之一,其被定义为:
1 | |
分布式系统也是一个孤立的系统,其中的网络与计算机节点(涵盖电源、主板、CPU、内存、网卡、硬盘等)等硬件会老化、会出故障,组件之间协同工作也会遇到负载过高、软件系统出现BUG等问题,这也是一个熵增的过程,并且因为熵增的必然性,分布式系统总是自发地或非自发地不断由有序走向无序,最终不可逆地走向失效不可用。为了保证分布式系统是有序可用的就必须逆熵增做功,即对其反熵增,分布式系统的反熵增过程与方法是:
- 可运维设计:软硬件的部署与升级设计、可视化设计、可观测性(监控、告警、日志、追踪)设计;
- 可服务设计:由团队解决故障以及提供服务的支持;
- 服务治理设计:熔断、限流、降级、隔离、容错,触使分布式系统保持在有序状态;
- 智能化设计:参数自我优化、故障自我判断、工作负载自我预测等;
- 动态平衡设计:动态平衡是一种设计理念,有进有出;
因此其中在分布式系统里将需要将可运维、可服务、可治理、可智能化、动态平衡的思想融合到架构设计与开发中。
数据守恒
能量守恒定律也是物理学的基本定律之一,其被定义为:
1 | |
在分布式系统里“数据”即是分布式系统的能量,因此参照“能量守恒”定义,这里我给分布式系统一个“数据守恒”定义:
1 | |
依据上节的定理推导,我们知道分布式系统里网络是不可靠的、消息传递是不可靠的、计算机节点是不可靠的、磁盘是不可靠的、内存是不可靠的、软件组件是不可靠的等等,这些过程都会丢数据,因此为了保证分布式系统里的“数据守恒”就需要对分布式系统进行数据可靠性设计:即:
- 分区设计、冗余设计、幂等性设计、端到端的校验设计、日志设计、事务处理设计,缓存的MESI设计等。
因此在分布式系统里将也需要将“数据守恒”的思想融合到架构设计与开发中。
小结
本文以物理学思维挖掘分布式系统的本质,推导出了分布式系统为什么需要这样的设计的缘由,并且文中阐述了分布式系统的基础理论、功能非功能、反熵增与数据守恒。日拱一卒,功不唐捐,分享是最好的学习,与其跟随不如创新,希望这个知识点对大家有用。另作者能力与认知都有限,”我讲的,可能都是错的“,欢迎大家拍砖留念。
作者简介
常平,中科大硕,DELL EMC 资深首席工程师,曾就职于Marvell、AMD,主要从事Linux内核以及分布式产品的交付、架构设计以及开发工作。
版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh
在遵循署名、非商业使用(以获利为准)以及禁止演绎的前提下可以自由阅读、分享、转发、复制、分发等。