动机
依据李善友老师的定义“第一性原理思维 = 逻辑奇点 + 公理化方法”,逻辑奇点即基石假设。根据这个第一性原理思维 ,本文解读了tensorFlow 2.0的架构设计,其涵盖了tensorFlow2.0的第一性原理、设计原则以及架构视图,本文的动机是展示第一性原理的架构设计思想在分布式系统架构设计中的应用。
TensorFlow 的第一性原理
欲从本质上理解Tensorflow,那么就需要找出tensorflow的第一性原理定义,再依据演绎法,从这个公理性质的定义演化出tensorFlow的设计理念、设计原则以及功能实现。这里首先把tensorFlow概念化,找出它的公理化定义以及基石假设,即TensorFlow是什么的定义。
通过tensorFlow官网以及Google,得到的6条关于tensorFlow的定义:
1.A machine-learning library based on dataflow programming.
2.TensorFlow is a free and open-source software library for dataflow and differentiable programming across a range of tasks.
3.TensorFlow is an end-to-end open source platform for machine learning.
4.TensorFlow computations are expressed as stateful dataflow graphs.
5.TensorFlow is an end-to-end open source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML powered applications.
6.TensorFlow Enterprise incorporates: Enterprise-grade support, cloud scale performance,managed services
从这6个定义中,可以概括出tensoFlow的公理化定义:
TensorFlow is an scalable end-to-end machine-learning platform based on stateful dataflow graphs programming,it has a comprehensive, flexible ecosystem.
即
tensorFlow是一个可伸缩的端到端的面向有状态的数据流图编程的机器学习平台,其具有一个全面而灵活的生态系统。
以及两个基石假设,即逻辑奇点:
- 可伸缩(scalable):可伸缩性是分布式的目的,分布式能力是TensorFlow的构建与运维能力,分布式能力是tensorFlow的隐性基石假设;
- 机器学习(machine learning):机器学习是Tensorflow的领域功能,是tensorFlow的显性基石假设。
从这个公理化的定义以及两个基石假设里可以推导出设计tensorFlow的作者们的对tensorFlow的几条类似定理性质的设计理念:
机器学习(machine learning): 指的是功能领域定位,依据这个设计定位,因此tensorFlow提供的是机器学习相关的功能,其涵盖数据、模型、策略、训练、推理等核心功能。
分布式:分布式能力是tensorFlow的构建与运维能力,从抽象的技术实现视角来看tensorFlow就是分布式框架+机器学习的lib库;
端到端(end-to-end): 端到端指的是“全程都包”的一种设计理念,用户输入原始数据,经过tensorFlow处理即可以直接得到可用的结果,这个结果可以直接服务于用户,用户无需关注tensorflow的中间过程如何。在tensorFlow里端到端的设计理念体现在 “准备数据 、定义模型、 训练模型、 评估模型、 保存模型以及使用模型”这几个过程,用户只要输入数据即可以得到可用的结果模型。
平台(platfrom):平台化,通常的软件平台指的是能够让用户自己在上面进行业务开发的软件系统,它将业务与技术解耦,用户可以基于这个平台开发自己的业务。其具有可用户自我定义的灵活性、用户可二次开发的开放性、以及接口标准化的特性。在tensorFlow里的平台化的设计理念体现在用户可以自由的定义自己的业务模型而无需关注里头的技术实现即可以得到想要的输出结果。
有状态(stateful):状态是指事物处于产生、发展、消亡时期或各转化临界点时的形态,有状态是指
“该服务的实例可以将一部分上下文的数据随时进行备份,并且在创建一个新的有状态服务时,可以通过备份恢复这些数据,以达到数据持久化的目的。”。
有状态服务在功能上可以保证数据的恰好一次,可以保证数据服务的强正确性,但是有状态服务需要维护大量的信息和状态,因此又引入了数据存储的复杂性,并且多了数据存储加载的过程,在性能方面要弱于无状态服务。而无状态服务不能保证数据的恰好一次处理,但是易于处理实例规模的伸缩性。tensorflow是有状态的设计理念,表明了tensorFlow可以保证数据处理的恰好一次的强正确性,但是又引入了数据存储与IO性能上的复杂性,需要平衡有状态服务下的正确性与复杂性就需要针对数据存储进行专门的设计。
数据流图(dataFlow graphs): 数据流图指的是用节点和有向边描述数学运算的有向无环图,其要素有数据源或宿、数据流、数据处理节点以及数据存储,其中节点代表数学运算等,而有向边代表节点之间的输入与输出关系、数据在边上流动。依据这个设计理念,TensorFlow依据下图的工作过程计算数据:
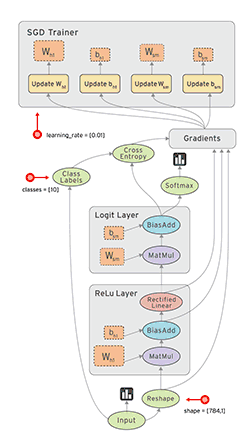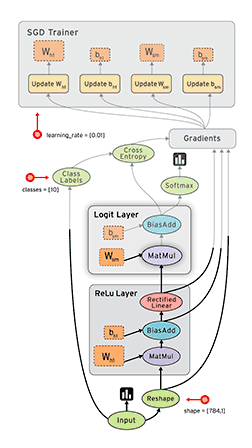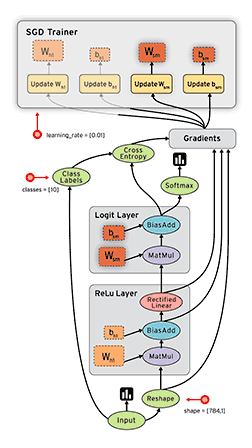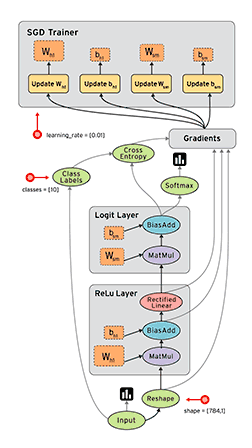
在这个数据流图里,tensorFlow里需要事先准备数据,接着定义运算操作,然后计算单元被同步或者异步地分配到不同的计算设备上比如CPU、GPU、TPU进行计算,其在边上流动的数据叫tensors。
编程(programming):可编程性,“编程就是指导计算机执行任务的行为”,编程是个动词,是为了让计算机干你想要干的事情。在面向对象编程里,程序=算法+数据结构+方法,依据这个设计理念,即用户可以依据一定的数据结构通过输入算法以及相应的工程方法,就可以指导tensorFlow执行用户想干的事情,其可以二次开发,具有灵活性以及开放性的特征。
生态系统(ecosystem):生态化,指的是tensorFlow的产品商业模式理念,围绕tensorFlow为核心建立一个完整的工具、库以及社区资源生态系统。
通过以上的分析,可以得出tensorFlow的第一性原理,即:tensorFlow是一个端到端的面向有状态的数据流图编程的机器学习平台,自带完整的产品生态系统,其逻辑基石为“分布式及机器学习”。就是这么简单的一句话,但是却是tensorFlow作者们的设计理念,整个tensorFlow的所有设计理念、设计原则以及功能实现都是依据这一句话来做指导的。
TensorFlow的设计原则
从tensorflow的官网可以看到几个关键词“easy,robust,powerful,ecosystem”,这几个词即是temsorflow的设计原则,tensorFlow的设计原则是定理性质的定义,其也从tensorFlow的第一性原理定义中推导出来。“端到端”代表了易用性,“平台化”、“可编程”代表了功能强大,“分布式”代表可高可用性、高可靠性,另外tensorFlow还有一个生态化的运营理念,灵活、开放、完整。
易用(Easy)
易用性的设计原则体现在与用户打交道的API接口层、模型的使用以及分布式训练:
模型制作简单,API容易调用,TensorFlow 提供多个级别的抽象接口,可以使用高阶的 Keras API 轻松地构建和训练模型
开发过程可调试,支持Eager Execution 进行快速迭代和直观的进行调试
- 训练过程简单,可以使用 Distribution Strategy API 在不同的硬件配置上进行分布式训练而无需更改模型定义
可靠(Robust,鲁棒性、可靠)
- 支持随时随地进行可靠的机器学习生产。支持在本地服务器、边缘设备、云端、web端轻松地训练和部署模型,而无需关注开发语言。TensorFlow Extended (TFX)可用于生产型机器学习, TensorFlow Lite可用于移动设备和边缘设备的推断, 而 TensorFlow.js 支持在web端中训练和部署模型
强大(powerful)
- 架构简单而灵活,支持最先进的模型,并且可以保证性能。借助 Keras Functional API 和 Model Subclassing API 等功能,TensorFlow 可以灵活地创建复杂拓扑并实现相关控制。TensorFlow 还支持强大的附加库和模型生态系统,包括 Ragged Tensors、TensorFlow Probability、Tensor2Tensor 和 BERT。
生态化(ecosystem)
- 生态化是产品的商业模型,灵活、开放、强大,tensorFlow具有完整的一个生态环境,其拥有一个包含各种工具、库和社区资源的全面灵活生态系统,可以让研究人员推动机器学习领域的先进技术的发展,并让开发者轻松地构建和部署由机器学习提供支持的应用
从tensorFlow 1.0 到tensorFlow 2.0 的升级,涵盖了API的易用性升级,动态图的支持、算法的更新、功能迭代以及文档完善,其本质目的还是遵循这四个设计原则,即简单、可靠、强大、生态化。如果只是追寻tensorFlow的版本迭代而不理解其背后的设计理念、设计原则,只会疲于奔命、知其然而不知其所以然。
TensorFlow 架构视图
逻辑架构视图
TensorFlow的逻辑架构视图体现了tensorflow的功能需求,如下图,tensorFlow的功能可分为训练、部署、可视化以及模型仓库。
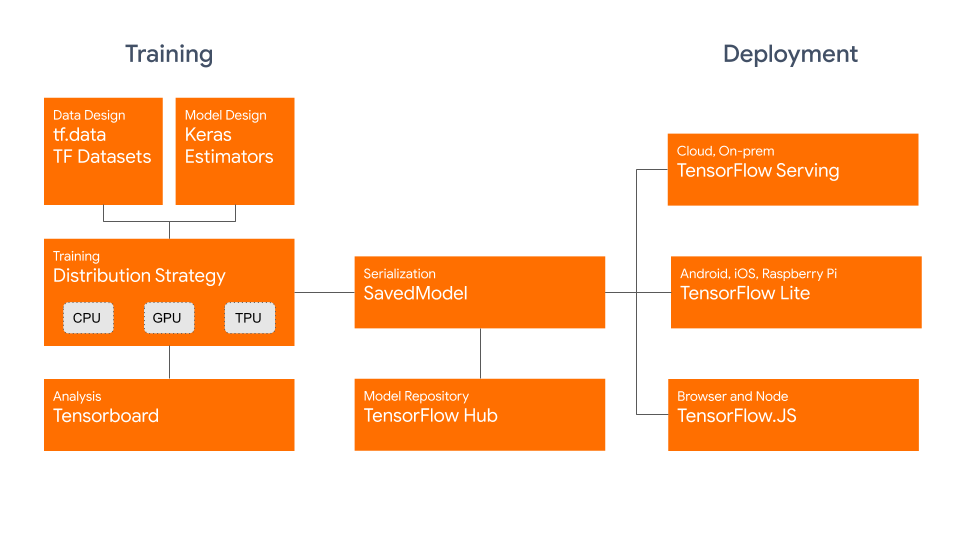
训练
- tf.data用于加载训练用的原始数据
- tf. Keras 或 Premade Estimators 用于构建、训练和验证模型
- eager execution 用于运行和调试
- distribution strategy 用于进行分布式训练,支持单机多卡以及多机多卡的训练场景
- SavedModel用于保存导出的训练模型,并且将训练模型标准化,作为 TensorFlowServing、TensorFlow Lite、TensorFlow.js、TensorFlow Hub 等的交换格式
部署
- TensorFlow Serving,即TensorFlow允许模型通过REST以及gPRC对外提供服务
- TensorFlow Lite,即TensorFlow针对移动和嵌入式设备提供了轻量级的解决方案
- TensorFlow.js,即TensorFlow支持在 JavaScript 环境中部署模型
- TensorFlow 还支持其他语言 包括 C, Java, Go, C#, Rust 等
可视化
- TensorBoard 用于TensorFlow可视化
模型仓库
- TensorFlow hub用于保存训练好的TensorFlow模型,供推理或重新训练使用
处理架构视图
TensorFlow的处理架构视图表明了数据处理的流程,其具有tensorFlow的运行期间的质量需求。
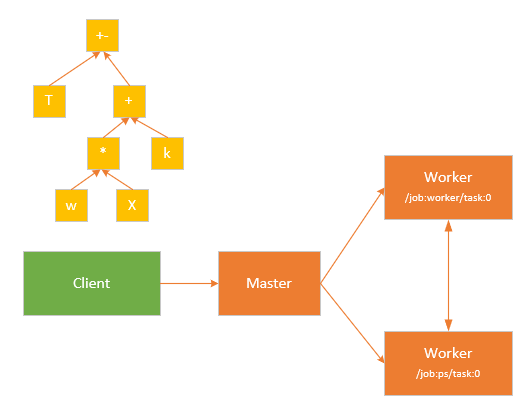
本图是分布式工作模式,“/job:worker / task:0” 和 “/ job:ps / task:0” 都是工作节点上执行的任务。“PS” 表示 “参数服务器”,负责存储和更新模型参数。
处理流程
1)客户端负责将整个计算过程转义成数据流图,并且启动计算发送到分布式主节点;
2)分布式主节点基于用户传递给的参数对整个完整的图形进行修剪,提取其中的子图,接着将子图拆分成不同部分,并将其分发到不同的进程和设备当中;
3)工作节点执行其收到的主节点分发给它的数据图片段,并且与其他工作节点 相互发送和接收计算结果;
4)内核计算单元,执行单个图形操作的计算部分。
数据处理期的质量与约束
TensorFlow分布式模式是构建在分布式之上的,其具有分布式系统自身的质量与约束需求:
TensorFlow的质量需求:性能指标:TPS、QPS、IOPS、Latency、ResponseTime、缓存抖动指标、缓存命中指标,可靠性指标: 6个9企业级代表,可用性指标:6个9企业级达标,数据一致性指标,可伸缩性,韧性,可观测性,可服务性,安全性,易用性,可运维性等
TensorFlow的约束需求:其可以是资源容量约束:CPU、磁盘、网络、线程、文件描述符个数,也可以是客户的约束、用户的约束等。
TensorFlow 2.0 的缺点
网络,开源的TensorFlow默认采用gRPC作为基础通信组件,违背“最佳物种”里的最佳原则设计哲学,机器学习本身是高吞吐量高性能要求的生产场景,而gRPC是基于HTTP2/Protobuf 协议通信的,而且发送接收都需要序列化,增加了网络传输的延时,并不是机器学习场景的最佳选择,但是好在TensorFlow也支持让你“DIY”的设计理念,例如在网络通信上支持GDP(GPU DIRECT)VERBS(IB,RDMA)以及MPI的扩展(“https://github.com/tensorflow/networking: Currently support building GDR, VERBS, and MPI extensions),这相当于把这一部分产品化的工作给了用户或者GPU、TPU之类的芯片原厂。优化手段:将PS算法、RING ALLREDUCE算法融合进MPI,再根据工程实践情况取舍“容错、可服务化、可运维化、智能化“的设计理念,抽象出一个新的分布式调度中间件以替换gRPC,目的是获取更好的性能、更高的GPU、TPU性价比。
计算,计算架构很有限还不能榨尽各种硬件的最佳性能。目前的分布式计算视图架构成熟的方案有:Parameter Server 架构以及Ring AllReduce架构,那么是否还有其它更好的架构,比如区块链的去中心化架构。
存储,存储应用容易被忽视,系统太过于复杂。TesnorFlow里涉及到存储的地方有:海量或非海量的原始数据存储、ETL好的数据的存储、PS架构中的训练参数以及模型的存储,训练好的模型的存储,如果这四个存储需求都是分散的存储系统,其实复杂度挺高,可以专门针对这种场景以及数据特性设计一个专门的机器学习存储系统,除了可以同时满足这四个场景的质量指标外,还将四个系统统一成一个,减少机器学习场景下的系统复杂度。
功能,功能的优化是无止境的,原则是要遵循客户需求适可而止。TensorFlow本质上也是分布式系统+机器学习领域的能力,除了机器学习的各种算法魔法的持续优化,分布式系统里的各种分布式算法也是适合迁移过来挖掘的,比如服务治理、路由负载均衡算法、集群视图变更、消息传输等。比如这么一个工程课题:“如何支持上万张训练卡的规模以及如何保证其质量可以达标?如何保证系统性能可以随着训练的卡数线性增长并且保证卡子的利用率在90%以上,同时可以保证训练过程的可靠性?”
产品,一个开源项目的功能特性大多是取舍的结果,就算是缺点往往也会很快演化迭代掉,因此从技术角度看待一个开源项目缺乏可持续性。但是从产品的角度来看,开源项目自带开源的先天弊端,其缺乏“价值与市场的锲合“度,这是开源项目的先天缺点,越成功的开源项目越无法避免,如果避免了这个缺点,开源项目反而是失败的,因为做的太好反而无法收费,团队没法存活,TensorFlow2.0开源版是一个开源的项目因此也逃脱不了这个缺点。从“项目与社区锲合”以及“产品与市场锲合”的角度来看,依据点赞数、fork数、下载量、用户使用量、社区文章阅读量这几个指标做度量,TensorFlow 2.0 开源版是一个非常成功开源的软件,但是从”价值与市场锲合“这个角度看,其离商业产品还是有一段距离。
开源项目往往是靠一些增值功能、企业级特性以及服务的支持收费而存活,这些特性即为价值与市场的锲合点,是商业客户愿意买单的地方,是商业产品与开源项目差异化所在,这些特性有:更好的性能、更加易用的部署与升级功能,可运维化、更加易用的可视化功能、安全、可观测、质量的可度量性,此外客户往往需要的不只是一个产品,更进一步需要的是行业解决方案。例如,tensorFlow企业版就说明了支持企业级特性、可云端伸缩性能以及无缝管理的支持,而TensorFlow2.0 开源版只是一个开源项目,还没达到这个层度。
因此,从产品的角度看,开源的tensorFlow2.0开源版只能算是一个成功的开源项目还不是商业产品以及解决方案,它只完成了“项目与社区锲合”以及“产品与市场锲合”这两个层次,因此商业化就要求我们需要把开源的tensorFlow2.0产品化、解决方案化。
小结
本文依据第一性原理架构设计思维模型解读了TensorFlow2.0。第一性原理思维模型我不是首创,分布式系统架构设计我不是首创,第一性原理思维模型在分布式系统架构设计中的应用我是首创。日拱一卒,功不唐捐,分享是最好的学习,与其跟随不如创新,希望这个知识点对大家有用。另作者能力与认知都有限,”我讲的,可能都是错的“,欢迎大家拍砖留念。
作者简介
常平,中科大硕,DELL EMC 资深首席工程师,曾就职于Marvell、AMD,主要从事Linux内核以及分布式产品的交付、架构设计以及开发工作。
参考资料
[1] https://blog.tensorflow.org/2019/09/tensorflow-20-is-now-available.html
[2] https://github.com/tensorflow/tensorflow
[3] https://en.wikipedia.org/wiki/TensorFlow
[4] https://www.tensorflow.org/about
[5] https://tensorflow.google.cn/guide/?hl=zh-CN
版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh
在遵循署名、非商业使用(以获利为准)以及禁止演绎的前提下可以自由阅读、分享、转发、复制、分发等。