本文为《下一个分布式存储系统,为万物互联的智能世界而发》升级版。
导言
纵观人类历史,各种技术变革都是以人类活动为中心,然后发明各种工具。石器时代,原始人发明了石器以及用火从而提升了生活品质和社会文明。现代社会,人类为了解决各种寂寞空虚冷吃穿住用行、生理和心理上的各种需求从而发明了各种社交空间、社交工具、网络购物、生活服务APP等,为了更好的服务这些应用场景,挖掘这些场景所生产的数据的价值,从而有了今天的各种大数据技术。
在互联网时代,数据主要来源于网页、APP以及一些相应的日志系统,而在万物互联的世界,数据还可以来源于有各种传感器、工业设备、监控设备、检测设备、智能家居、自动驾驶等。大数据的四个特征:数据量、时效性、多样性、价值密度在万物互联的场景下被进一步的深化,这就意味着商业成本以及技术成本的增加。
理论奠定技术的基础,业务驱使技术的变革。在万物互联的智能时代,我们有一个愿景: 能够将万物互联下生成的海量原始数据转化为可用的信息以及行为决策,并且这个转换的时间差需要能够接近于零。通过现有技术的组合,技术人员打造了工业物联网平台从而希望能达成这个愿景。
动机
现有的工业物联网大数据处理平台很多是基于开源的技术“D-I-Y”而来,它是一个”DIY“系统,往往为了一个功能而引入一个复杂的组件,这就容易造成平台只关注功能而忽略“质量与约束”,在复杂之上堆积复杂,致使客户商业成本、技术成本以及运维成本高昂。
从商业角度来说,在构建物联网大数据处理平台的时候,大家都用的开源的技术,构建出来的平台同质化严重,那么有个问题需要回答的就是:“大家都用的同样的开源技术,客户凭什么需要买单你的?”
从产品的角度来看,一个好的产品既能“顶天”,还能“立地”,它除了能有自己独到的灵魂与创新,还能将自己扎根于用户,替客户解决实际的生产问题,而不是又给客户带来新的问题。然而现有的工业物联网大数据处理平台除了给客户解决了一部分的生产问题,但是又引入了新的问题:成本高昂以及平台质量还往往难以达标。
新的技术不仅可以来源于已有技术的组合与进化,还可以来自于对现有现象的理解与征服。因此,出于对现有的工业物联网平台的理解以及降低客户的商业成本、技术成本以及运维成本的目的,这里提出了重构工业物联网大数据平台存储栈的理念。工业物联网平台
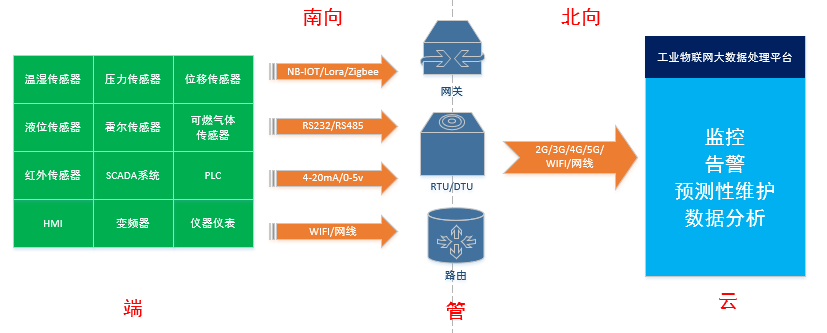
如下图所示,通常一个工业物联网平台是以 “云-管-端”三部分组成的,类似x86服务器主板南桥北桥的叫法,工业物联网平台也是如此,在“管”的左边跟外设传感器之类打交道的地方我们称之为“南向”,跟数据处理相关“管”的右边我们称之为“北向”。南向由各种传感器以及SCADA/PLC/HMI组成,负责数据的采集,然后数据再经过RTU、DTU、网关或路由传输到云端的工业大数据处理平台进行处理,从而完成监控、告警、预测性维护、分析等功能。
流数据/时序数据
如下表所示,工业物联网平台南向传感器采集的数据,具有时间属性并且自带标签与数值,每条数据代表一个监测指标并且反应数值的变化,同时这些数据又随时间延续而无限增长,因此被称之为流数据或时序数据。
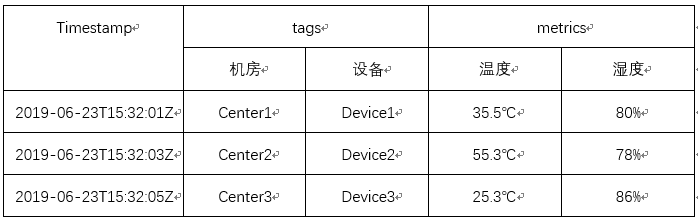
南向采集数据的设备虽然多种多样,然而本质上它们的数据格式是一样的,都由“timestamp,tags,metrics”这三部分组成。数据格式看上去是很简单的,但是对于数据处理系统来说复杂度的来源在于:
- 数据自带时间戳具有时间有效性,这意味着数据处理的实时性;
- 数据都是小数据,这意味着数据存储系统需要对此进行专门的高性能设计;
- 数据随时间延续而无限增长,这意味着数据的无限性;
- 数据到达的速度有快有慢、负载有高有低,这意味着灵活又细粒度的资源弹性需求;
- 数据有序、无序、持久化以及复杂的传输环境而又要保证数据处理结果的唯一正确性。
这是几个特性转换成存储技术的语义对应着: 实时性、高性能、无限性、可伸缩性以及恰好一次:持久化、有序、一致性以及事务。从 存储的视角来说,每种类型的数据都有其原生的属性和需求,对应有最佳的适用场景以及最合适的存储系统。那么目前又有哪种存储系统最适合用于 “流数据”呢?正如当前技术条件下最适合 “流数据”计算的是类似Flink这样的分布式流计算应用,最适合“流数据”的我们认为应当是专门针对流数据而设计的分布式流存储系统。
工业大数据处理
工业物联网平台北向负责大数据的处理,万物互联场景下无限量的数据给数据处理技术带来巨大的挑战与压力,不同的应用场景意味着不同的数据处理要求与复杂度,要把这些不同的甚至矛盾的数据处理要求都很好的综合在一个大数据处理系统里,对现有的大数据处理技术来说是个非常大的挑战,比如无人车的处理要求毫秒甚至纳秒级的数据处理实时性、而有些工业设备数据只需要分析历史数据,要让一个大数据处理系统既能能处理历史数据又能提供毫秒级甚至纳秒级的实时性处理能力还能应对各种不同格式不同传输场景的数据,而且每种数据处理都能达到这些应用场景原生指标的处理需求,相信这样的场景对工程技术人员来说是个很大的挑战。为了解决上述问题,按照现有的成熟的技术能力,通常开发人员采用类似Lambda架构(如下图)这样的大数据处理平台组合了各种复杂的中间件来达成这个数据处理的目标。
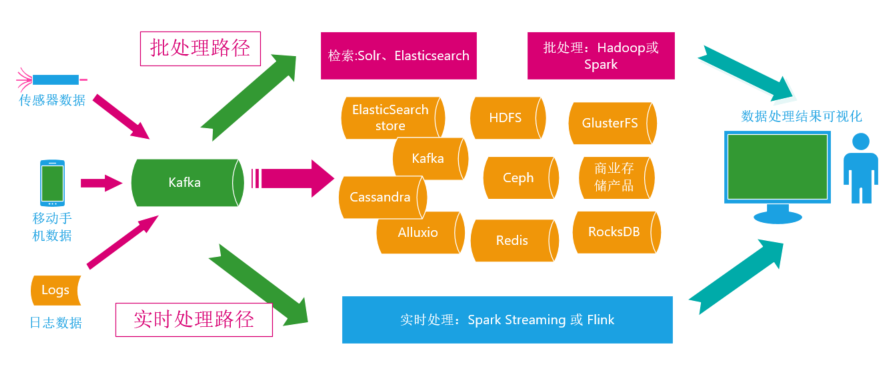
Lambda架构即支持批处理也支持实时处理,能应对数据的多样性、具有容错功能、复杂性分离、能处理流式数据也能处理历史数据等优点,但是缺点也很明显:批处理一套独立的数据处理路径,实时处理又一套数据处理路径,然后还要合并结果再输出展示,同时系统里同样的数据存在存储多份的问题,比如同样的数据在Elasticsearch里有、HDFS里有、ceph里有、Kafka里也有,除了这些甚至还存在其他一些复杂的存储组件,而且同样的数据还都是多份冗余的,因此存储成本太高太过于复杂。Lambda架构里为了提供一个功能却引入一个组件,在复杂之上堆积复杂,存储成本、开发与运维成本都太过于复杂。
那么应当如何解决Lambda架构带来的这些缺点?以数据流向为核心重构大数据处理平台是一个比较好的方案,它具体包括数据的采集、聚合、传输、处理、展示等。依据这种设计理念我们可以推出一个端到端的原生的流式大数据处理平台:原生的流式计算加上一个原生的流式存储并且可以平衡商业成本与技术成本。
流式计算可以采用Flink,然而并没有发现当前有合适的流式存储可以使用,因此,综合思考万物互联场景下的数据处理场景也需要一个原生的分布式流存储系统,重构Lambda架构里的存储栈,使得分布式流计算加上分布式流存储即为原生的流式大数据处理系统,同时还能很好的平衡商业成本与技术成本之间的关系。
设计思路
数据中台
通常数据中台的目标是:“治理与聚合数据,将数据抽象封装成服务提供给前台业务使用”,因此,数据的治理、聚合以及抽象是数据中台的关键点。当前的大数据处理平台,不管是Kappa架构还是lambda架构,数据的存储都是多组件化、多份化的。比如同样的数据在Kafka里有、在HDFS里有、在Elasticsearch里又有,有些用户还使用了更多的存储中间件,而且这些数据还是多份冗余的。这一方面增加了数据的存储成本,另一方面也降低了数据的可信性、可靠性、合规性,给数据标准化以及数据的重复利用带来了困难,不利于数据的分享、合规、降低成本以及安全可靠地支持业务和决策。因此需要对数据进行治理、聚合以及抽象。通过使用分布式流存储,大数据处理平台的架构可以进化成”分布式流计算+ 分布式流存储“这样的原生流式数据处理平台架构,这也体现了“数据中台”的理念。
流原生架构
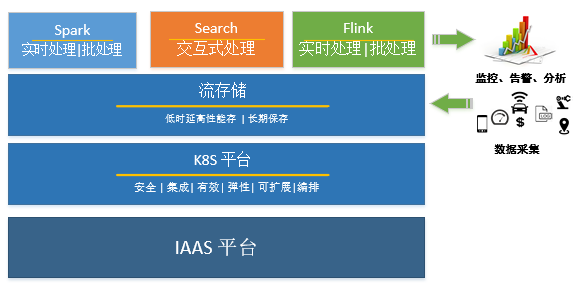
依据 “流原生” 的架构设计哲学以及数据中台的理念,这里提出”分布式流计算+ 分布式流存储“这样的原生流式工业大数据处理平台的架构理念,不同于Lambda架构与Kappa架构,流原生架构最主要的工作是对数据进行了治理、聚合与抽象,使得工业大数据平台的计算层通过统一的数据API接口调用底层的流存储系统。如下图所示,Spark,Flink以及检索系统等都调用统一的流存储接口,从而减少了平台复杂度以及降低数据存储成本和运维成本。
算子编排
工业大数据处理平台虽然很复杂,然而抽象到最后就一个简单的数学公式:“Y = F(X)”,输入数据x,经过F算子计算再输出结果Y,数学表达式并不复杂,如同质能方程E=mc²,但是从理论到落地还有一个浩大的工程,Y=F(x)其复杂度主要来源于:
每个数据算子都认为是一个Y=F(x),需要对无数个这样的算子进行高性能的计算,算子无限性;
需要对无限个随时可能乱序的Y=F(x)算子进行编排、组合、拆分,算子编排。
- 需要对无限个Y=F(x)算子的中间结果进行持久化、保序,以及保证计算结果的正确性,算子结果确定性;
因此需要一个专门的数据处理架构来解决这些复杂度。
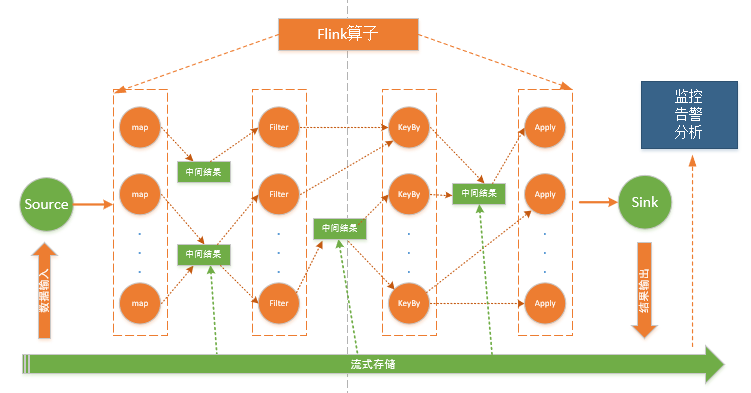
如上图所示,“流原生”的Flink计算加上“流原生”的存储管道组成了“流原生”的大数据处理平台。数据从分布式流存储输入经过map算子计算,输出中间计算结果到分布式流存储里,数据又从分布式流存储里读入到Filter算子里,再经过计算,中间结果放到了分布式流存储里,再最后的计算结果经过Apply算子的计算放到了目的地的分布式流存储里。这个过程体现了算子编排和管道式编程的设计哲学,在这里分布式流存储起了大数据处理平台里的管道的作用。
分布式流存储
分布式流存储的产品定位是给万物互联这样的应用场景服务的,从技术角度来看它具有自身的特点,正如标题里提到的三个关键词: “分布式”、“流”、“存储”。首先是分布式的,它具有分布式系统本身所具有的一切能力,接着表示是专门给流式数据设计和实现的,最后的存储表示的是一个原生的存储解决方案,它讲究数据的 可靠性、持久化、一致性、资源隔离等,它从 存储的视角处理流数据。分布式流存储针对 “流数据” 的自身属性以及相应的特殊的业务需求场景做了专门的设计与实现,下面从 命名空间、业务场景、无限性、可伸缩性、恰好一次、字节流、数据管道、租户隔离、海量小文件的角度依据 最佳实践原则 讲述了为什么需要专门设计和实现一个流式存储系统。
命名空间
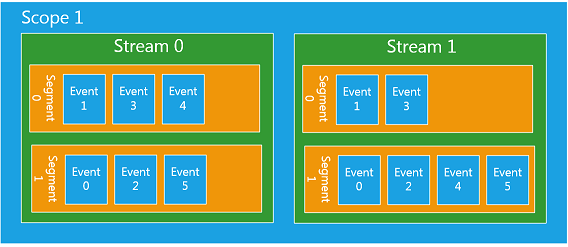
通常,块存储系统以分区、目录、文件,文件存储系统以目录、文件,以及对象存储以租户、桶、对象来定义数据的存储路径以及命名空间,而流存储系统则以范围(scope)、流(stream)、段(segment)、事件(event)来描述数据的存储路径以及命名空间。
| 类型 | 命名空间 |
|---|---|
| 块存储 | 分区、目录、文件 |
| 文件存储 | 目录、文件 |
| 对象存储 | 租户、桶、对象 |
| 流存储 | 范围、流、段、事件 |
在流存储系统里,如下图所示,数据的组织形式被抽象成范围、流、段和事件,范围由流组成,流由段组成,段由事件组成,事件由字节(bytes)组成。
业务场景
在自动驾驶的场景里采用分布式流存储,我们可以这样处理自动驾驶的数据:给每一辆无人车定义一个1TB存储空间的范围,车上的每个传感器都归属于一个流,传感器上报的事件都在段内持久化。再假设每辆车都有1000个传感器(实际情况只多不少),那么10万辆车就需要定义1亿个流,可以想象要进行这种规模的隔离也就只有这种专门针对流数据而设计的流存储系统能够支持。
在工业厂房的场景下,还可以这样定义工业设备的数据:给一个厂房里的每台设备定义一个范围,每台设备里的每个传感器都对应一个流,传感器上传的事件数据保存在流内的段里,这样就很方便的对工业设备进行了大规模的租户数据隔离。
因此,以“范围、流、段、事件”的方式很方便的进行了大规模的租户隔离保证了用户信息安全同时又进行了存储资源配额的隔离。
数据无限性
无限性是分布式流存储最为重要的设计原则。从流数据的角度来看,数据是大量、快速、连续而又无限的,这就给流存储系统的设计与实现带来极大的困难,无限的数据使得存储系统必须能支持连续且无限规模的数据流,光这一点就对存储系统的可扩展性要求非常的高,同时还要求存储系统能够根据到达的数据量动态而又优雅地进行扩容与缩容。从技术与成本的角度来看,数据无限性意味着冷热数据分离,长期不用的数据淘汰到长期存储系统里,热点数据需要缓存,同时还需要能支持历史数据的读取与实时数据的读取与写入。
可伸缩性
可伸缩性也是分布式流存储最为重要的设计原则之一,而且流存储里的可伸缩性要求还是自动化的资源细粒度的可伸缩。通常,在云原生的场景下,资源的缩放是以主机、虚机或容器为单位的,这样的缩放对流存储来说粒度太大。在流存储的场景下需要能够以数据的“流段”为单位,比如一个流段2MB,那么就需要能支持一次自动扩容或缩容2MB的存储空间。另外在流存储里还要求写入与读取对数据子集的操作是解耦分离的,并且写入与读取二者之间跟数据流段还要有一个合理的平衡。
恰好一次
恰好一次也是分布式流存储最为重要的设计原则之一,恰好一次意味着数据的可持久化、有序、一致性以及事务性的支持。持久性意味着一旦得到确认,即使存储组件发生故障,写入的数据也不会丢失。有序意味着读客户端将严格按照写入的顺序处理数据。一致性意味着所有的读客户端即使面对存储故障、网络故障也都会看到相同的有序数据视图。事务性写入对于保证Flink这样的计算应用处理结果的完全正确是非常必要的。
字节流
分布式流存储里采用字节流的格式组织数据而不是像消息系统里采用消息报文的方式,这意味着接口的通用性。二进制的字节流是与数据格式无关的,字节流可以组成事件封装在分布式存储的流段里。而消息系统里数据是消息头消息体的格式封装的,在兼容性上不如字节流。
数据管道
在存储界通常喜欢用跑车、卡车、渡轮来比喻块存储、文件存储以及对象存储,打个比方来说块存储类似跑车:极快、极稳、装的人少、成本高;文件存储类似卡车:快、稳、装的人比跑车多,但是没跑车那么快;对象存储类似渡轮:可以装非常多的货,讲究量大、成本低;那么分布式流存储像什么呢? 在我们的定义里它就像管道:数据如同流水一般流过管道,又快又稳源源不断而又永无止境。
租户隔离
分布式流存储从一开始设计的时候就将”租户隔离“作为其基本特性进行实现,”隔离“是分布式流存储的最基本的特性之一,在分布式流存储里租户隔离不只是租户B绝对不能看的到租户A的任何信息这样的信息安全层面的隔离,它支持范围、流、段、事件层面的隔离还将支持的租户规模作为设计的目标之一,在分布式流存储里单集群需要能支持千万量级起的租户数,另外还有资源、命名、可视空间、权限以及服务质量层面的隔离。
海量小文件
对巨量小文件的支持是分布式流存储的设计原则之一。正如前面提到的,万物互联下的海量数据来源于传感器,而传感器上传的数据都是类似温度、地理位置、告警信息这样的几个字节几个字节的小数据,这就意味着在万物互联的场景下会有巨量的小数据上传,而且90%以上的数据操作行为都是写入。为了保证数据写入的性能以及可靠性、正确性、持久性以及保证介质的使用寿命降低成本,这也需要存储系统针对这种业务场景进行专门的设计。
在分布式流存储里每个事件第一步是被仅附加写入一个缓存的段内进行封装的,在段达到一定的尺寸(比如64MB)后会被封闭不再写入,这时再将整个段写入下一级的持久化存储里。通过这样的设计,实现小数据在缓存里封装成大块的数据,再将大块数据写入持久化存储设备的方式保证了存储系统整体的性能。
小结
电影《一代宗师》里提到习武之人有三个境界:“见自己,见天地,见众生”。做技术做产品也同样如是,“三见”如同一体三面不可分割,认知上从关注自己到关注格局创新,再扎根到用户当中替用户解决有价值的实际问题。现有的工业物联网大数据处理平台有创新也有替客户解决了部分工业数据处理的难题,但是还是属于一个”DIY“的系统,离产品化还有距离,因此需要我们继续扎根下去替客户解决新的实际问题。
综上所述,在万物互联的智能世界里,为了实现将海量数据近实时转化成信息和决策的愿景,除了流式计算应用还需要一个流式存储系统,未来已来,已有开源的分布式流存储系统正走在这条路上。另本文仅为作者愚见,与任何组织机构无关,作者能力也很有限,如有不足之处欢迎留言批评指正。
问题思考
最后给大家留一个思考题:如果让你来设计一个工业物联网平台产品,你会如何定义它的产品灵魂?
作者简介
常平,中科大硕,10年+数据相关经验,主要工作背景为分布式系统、存储、缓存、微服务、云计算以及工业物联网大数据,现就职于DELL EMC。个人技术博客:https://changping.me
版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh ,可以自由阅读、分享、转发、复制、分发等,限制是需署名、非商业使用(以获利为准)以及禁止演绎。