导读
日拱一卒,功不唐捐,分享是最好的学习,一个知识领域里的 “道 法 术 器” 这四个境界需要从 微观、中观以及宏观 三个角度来把握。微观是实践,中观讲套路,宏观靠领悟。本系列文章我把它命名为《分布式系统架构设计三十六式》,讲诉分布式系统里最重要的三十六个虚数的中观套路,而微服务的本质也是分布式,因此搞明白这三十六个最重要的知识点也就同时能搞明白微服务。
实现一个分布式系统通常会面临三大难题: 故障传播性、业务拆分与聚合以及分布式事务 。本系列中的服务治理章节主要是为了解决故障传播性的难题,它包括: 隔离、熔断、降级、限流、容错以及资源管控 ,本文将讲诉服务治理里的 “5F容错” 模式,下一篇将讲诉 “关联资源管控” 模式。
动机
出错重试 :在分布式系统里,系统里出现故障时需要进行出错处理,当执行熔断或降级处理策略时,通常也需要有相应的重试处理策略,而这些策略又需要根据不同的业务场景进行设计。超时处理 :在分布式系统里,为了保证高可用以及高可靠性,也需要相应的超时处理策略,比如超时后怎么重试?超时后重试几次还是失败应该怎么处理?超时处理是让用户感知还是不让用户感知?
5F容错模式设计思路
这里借用Dubbo里的概念讲述5种容错处理策略,我定义它们为5F容错法,下图是一个简单的分布式系统逻辑架构图。
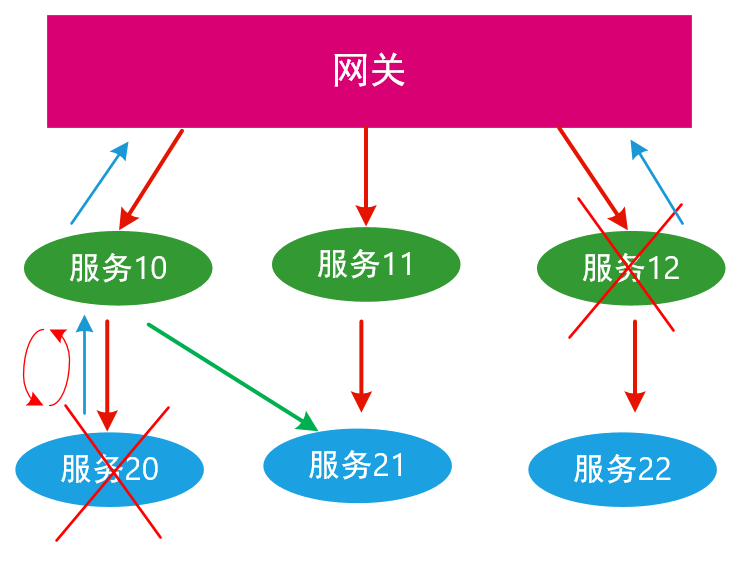
Failover 失败切换
在分布式系统里,为了保证高可用性以及高可靠性,通常会对服务或者设备进行冗余,当一个服务或者设备出现故障时,就直接切换到另外一个服务或设备上,这种设计模式叫做 故障切换。
如上图所示,服务10本来是路由到服务20的,当服务20出现故障时,从服务10路由到服务20的请求,服务20并没办法处理,这时候服务10收到一个请求超时的返回,发现服务20没法处理这个请求,为了保证高可用性,服务10的请求就被路由到服务21,从而保证了服务的高可用与可靠性,这个过程用户是不感知的
Failfast 快速失败
快速失败是指当发现服务请求调用失败时,就立即上报故障,快速失败的一个重要目的是用于检测错误以便降低出错成本为系统提供足够的信息来保证高可用与高可靠,这个过程用户是感知的。
比如上图中服务20出现故障就快速上报故障给服务10,然后服务10就可以采用Failover策略将服务请求切换到服务21,从而避免更多的不可用时间。
Failback 失败恢复
Failback跟Failover有点类似,但是Failover是发现故障时就把请求切换到别的服务或设备上去,而Failback是在发现下游的故障后,把请求扔到一个临时的设备或者服务或者组件(比如队列)上,然后待下游故障修复后,重新同步数据以及请求,把这些数据或者请求还原到原来的服务或者设备上。比如上图所示,在服务20出现故障后,服务10发过来的请求被放到一个临时的队列里,然后在服务20在一定的时间内被恢复后,又把这些请求从队列中恢复发到服务20,这个过程用户时不感知的。
Failsafe 失败安全
FailSafe 是指系统出现故障时可以直接忽略这个故障,不进行相应的故障处理,在Failsafe的场景下,故障不会给系统带来伤害,对服务质量也不会有什么影响,简单的处理方式就是把故障的信息写到日志里保存。
Forking 请求分叉
在Forking策略下,将请求进行裂变下发,只要一个请求处理成功整体请求就成功。比如上图所示,一个读请求到网关后被分裂成同样的请求三份,然后这三个请求被下发到服务10,11,12,只要有一个请求处理成功就返回成功。
小结
本文讲诉了服务治理里的 “5F容错”模式,内容也没有多少,但是需要应用合适保证服务质量却并不容易,在应用的时候一般会根据实际的业务场景进行策略组合使用,在前一篇《分布式系统架构设计三十六式之服务治理-横向限流模式》里讲诉了分布式系统服务治理的横向限流模式。另作者能力与认知都有限,欢迎大家拍砖留念。
作者简介
常平,中科大硕,10年+数据相关经验,主要工作背景为分布式系统、存储、缓存、微服务、云计算以及大数据,现就职于DELL EMC。个人技术博客:https://changping.me
版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh ,可以自由阅读、分享、转发、复制、分发等,限制是需署名、非商业使用(以获利为准)以及禁止演绎。
参考资料
[1]http://dubbo.apache.org/zh-cn/docs/source_code_guide/cluster.html