导读
日拱一卒,功不唐捐,分享是最好的学习,一个知识领域里的 “道 法 术 器” 这四个境界需要从 微观、中观以及宏观 三个角度来把握。微观是实践,中观讲套路,宏观靠领悟。本系列文章我把它命名为《分布式系统架构设计三十六式》,讲诉分布式系统里最重要的三十六个虚数的中观套路,而微服务的本质也是分布式,因此搞明白这三十六个最重要的知识点也就同时能搞明白微服务。
实现一个分布式系统通常会面临三大难题: 故障传播性、业务拆分与聚合以及分布式事务 。本系列中的服务治理章节主要是为了解决故障传播性的难题,它包括: 隔离、熔断、降级、限流、容错以及资源管控 ,本文将讲诉服务治理里的 “熔断” 模式。
动机
在分布式系统里经常会遇到这样的场景:
系统负载突然过高,比如突发的访问量、过多的请求并发数以及过多的IO等都会造成某个节点故障,比如节点A,然后节点A挂了,又把负载转给节点B,然后节点B又负载过高,接着B又挂了,就这样一连串的挂过去从单点故障造成系统级的级联故障。
当一个服务出现故障时,希望这个服务能在一个时间段内恢复,在请求被拒绝后隔一段时间再自动的去探测服务的可服务性。
对应这两个场景,我们希望在分布式系统里能避免级联故障、提供快速失败快速恢复服务的能力,因此,这里引出 “熔断模式” 。
熔断模式
熔断模式也称之为断路器模式,英文单词是“circuit breaker”,“circuit breaker”是一个电路开关,其基本功能是检测到电流过载就中断电路,在检测到电流正常时又能自动或手动恢复工作,从而保护断路器背后的电源设备安全。这里需要将”断路器“与 “保险丝”进行区分,断路器可以通过手动或自动的复位从而恢复正常工作,而保险丝是运行一次必须更换。
实现一个分布式系统通常会面临三大难题: 业务拆分与聚合,分布式事务以及故障传播性。本系列中的服务治理章节主要是为了解决故障传播性的难题,它包括:隔离、熔断、降级、限流、容错以及资源管控,本文将讲诉服务治理里的 “熔断”模式。
在分布式系统里 “熔断模式”的设计思想来源于此,当系统里响应时间或者异常比率或者异常数超过某个阈值时,比如超时次数或重试次数超过某个阈值就会触发熔断,接着所有的调用都快速失败,从而保证下游系统的负载安全,在断开一段时间后,熔断器又打开一点试着让部分请求负载通过,如果这些请求成功那么断路器就恢复正常工作,如果继续失败,则继续关闭服务走快速失败通道,接着继续这个过程直到重试的次数超过一定的阈值从而触发更为严重的“降级模式”。
熔断模式设计思路
下图是一个熔断模式的设计思路:
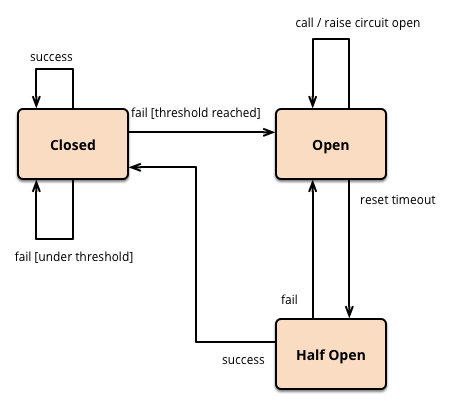
图片来源于引文[2],版权归原作者所有
首先熔断器是处于闭合(closed)状态的,如果请求超时次数,异常数或者异常比率超过一定的阈值则熔断器会被打开;
接着熔断器处于打开(Open)状态,所有走到这个路径里的请求会走快速失败通道从而避免负载下行,但是这里不会一直都是打开的,过一个时间周期会自动切换到半打开(Half-open)状态;
在接下来是半打开(half-open)状态,在这里认为之前的错误可能被修复了,因此允许通过部分请求试着看看能不能处理成功,如果这些请求处理成功,那么就认为之前导致失败的错误已被修复,此时熔断器就切换到闭合状态并且将错误计数器重置。如果这些试着发送的请求还是处理失败,则认为导致之前失败的问题仍然存在,熔断器切回到打开方式,然后开始重置计时器给系统一定的时间来修复错误。半打开状态能够有效防止正在恢复中的服务被突然而来的大量请求再次打挂;
接着重复以上过程,直到半打开状态重复的次数达到一定的阈值发现故障还没被修复,从而触发”降级“状态
小结
本文讲诉了服务治理里的 “熔断”模式,在前一篇《分布式系统架构设计三十六式之服务治理-隔板模式》里讲诉了分布式系统服务治理的隔板模式。另作者能力与认知都有限,欢迎大家拍砖留念。
作者简介
常平,中科大硕,10年+数据相关经验,主要工作背景为分布式系统、存储、缓存、微服务、云计算以及大数据,现就职于DELL EMC。
版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh
在遵循署名、非商业使用(以获利为准)以及禁止演绎的前提下可以自由阅读、分享、转发、复制、分发等。