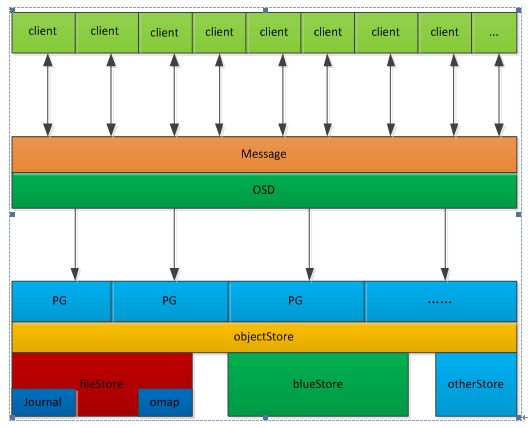
ceph逻辑架构图
ceph后端支持多种存储引擎,以插件化的形式来进行管理使用,目前支持filestore,kvstore,memstore以及bluestore,目前默认使用的是filestore,但是目前bluestore也可以上生产。下图是ceph的逻辑架构图:
Firestore存在的问题是:
在写数据前需要先写journal,会有一倍的写放大;
若是另外配备SSD盘给journal使用又增加额外的成本;
filestore一开始只是对于SATA/SAS这一类机械盘进行设计的,没有专门针对SSD这一类的Flash介质盘做考虑。
而Bluestore的优势在于:
减少写放大;
针对FLASH介质盘做优化;
直接管理裸盘,进一步减少文件系统部分的开销。
但是在机械盘场景Bluestore与firestore在性能上并没有太大的优势,bluestore的优势在于flash介质盘。
FileStore逻辑架构
下图为ceph filestore逻辑架构图:
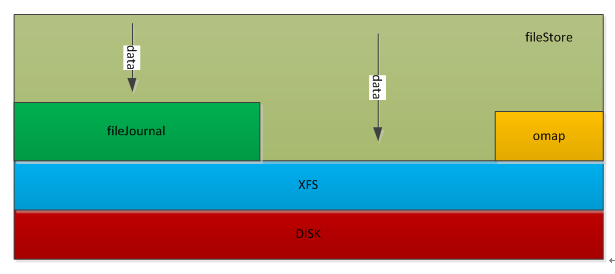
首先,为了提高写事务的性能,FileStore增加了fileJournal功能,所有的写事务在被FileJournal处理以后都会立即callback(上图中的第2步)。日志是按append only的方式处理的,每次都是被append到journal文件末尾,同时该事务会被塞到FileStore op queue;
接着,FileStore采用多个thread的方式从op queue 这个 thread pool里获取op,然后真正apply事务数据到disk(文件系统pagecache)。当FileStore将事务落到disk上之后,后续的读请求才会继续(上图中的第5步)。
当FileStore完成一个op后,对应的Journal才可以丢弃这部分Journal。对于每一个副本都有这两步操作,先写journal,再写到disk,如果是3副本,就涉及到6次写操作,因此性能上体现不是很好。
Bluestore逻辑架构
下图为ceph bluestore逻辑架构图:
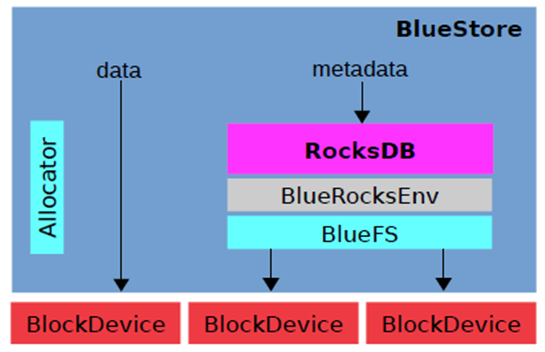
Bluestore实现了直接管理裸设备的方式,抛弃了本地文件系统,BlockDevice实现在用户态下使用linux aio直接对裸设备进行I/O操作,去除了本地文件系统的消耗,减少系统复杂度,更有利于Flash介质盘发挥性能优势;
为了惯例裸设备就需要一个磁盘的空间管理系统,Bluestore采用Allocator进行裸设备的空间管理,目前支持StupidAllocator和BitmapAllocator两种方式;
Bluestore的元数据是以KEY-VALUE的形式保存到RockDB里的,而RockDB又不能直接操作裸盘,为此,bluestore实现了一个BlueRocksEnv,继承自EnvWrapper,来为RocksDB提供底层文件系统的抽象接口支持;
为了对接BlueRocksEnv,Bluestore自己实现了一个简洁的文件系统BlueFS,只实现RocksDB Env所需要的接口,在系统启动挂在这个文件系统的时候将所有的元数据都加载到内存中,BluesFS的数据和日志文件都通过BlockDevice保存到底层的裸设备上;
BlueFS和BlueStore可以共享裸设备,也可以分别指定不同的设备,比如为了获得更好的性能Bluestore可以采用 SATA SSD 盘,BlueFS采用 NVMe SSD 盘。