Pravega架构
”技术在某种程度上一定是来自此前已有技术的新的组合“ – 《技术的本质》,布莱恩·阿瑟
Pravega为连续而又无限的数据提供了一种新的存储原语 - 流存储,然而Pravega也并不是凭空发明出来的,它是以前成熟技术与新技术的组合,例如Pravega的 范围、流、段、事件就跟Kafka的主题、分区、段、消息对应,而一层存储又用了Bookkeeper,协调器用了Zookeeper等。
设计原则与目标
持久化:在客户端确认写入前,数据被复制并且写入磁盘;
保序:段内严格保序;
恰好一次:支持恰好一次语义;
轻量级:一个流就如同一个文件,可以在单集群里创建千万量级起的流;
可弹性:可基于负载和吞吐量智能地动态扩展或者收缩流;
无限性:存储空间大小不受单个节点的容量限制;
高性能:写入延迟低于10ms,吞吐量仅受网络带宽限制,读模式(例如:追赶读)不影响写性能;
Pravega设计创新
支持“无限流”分层
零接触动态缩放
根据负载和SLO自动调整读/写并行度
没有服务中断
- 无需手动重新配置客户端
- 无需手动重新配置服务资源
智能工作负载分配
- 无需为峰值负载过度配置服务器
I / O路径隔离
- 支持尾部写入
- 支持尾部读
- 支持追赶读
支持“恰好一次”事务
逻辑架构
下图为Pravega的逻辑架构图:
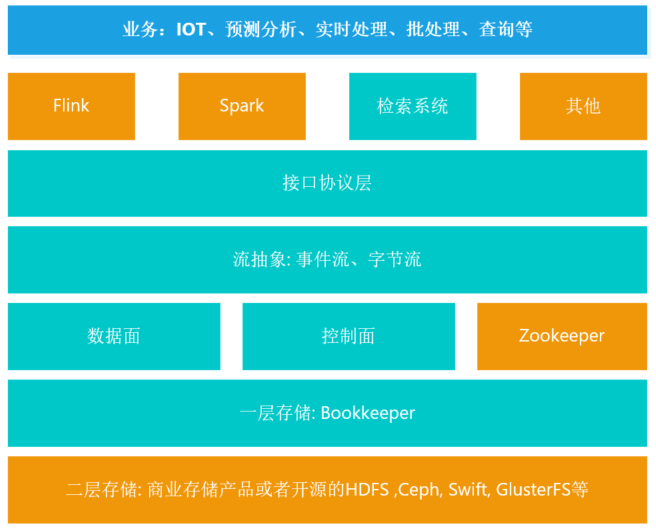
- 首先,Pravega提供了一个用Java编写的客户端库,抽象出了流协议层接口,用于支持客户端应用,例如Flink、Spark以及一些检索系统等;
- 其次,Pravega实现了一个流数据抽象层,用于事件流和字节流的抽象;
- 再者,从整体架构上来讲Pravega符合软件定义存储的设计规则,其控制面与数据面分离,数据面的集合统称为段存储层,控制实例组成控制面,实现了检索流信息、监控集群、收集相关指标等功能,同时为了实现高可用,通常有多个(建议至少3个)控制实例同时对外提供服务。
- Pravega采用Zookeeper作为集群中的协调组件。
- Pravega的存储系统由两部分组成:第1层为短期存储层,主要关注性能,用于存储热点数据,由bookkeeper实现,保证了存储系统的低时延、高性能。第2层为长期存储层,主要关注成本,提供数据的持久性以及长期存储,由开源的或者商业的存储产品组成。第1层保留热点数据,随着第1层中数据的老化,数据将自动分层流入第2层。
数据架构
下图展示了Pravega的数据架构图以及数据流分层:
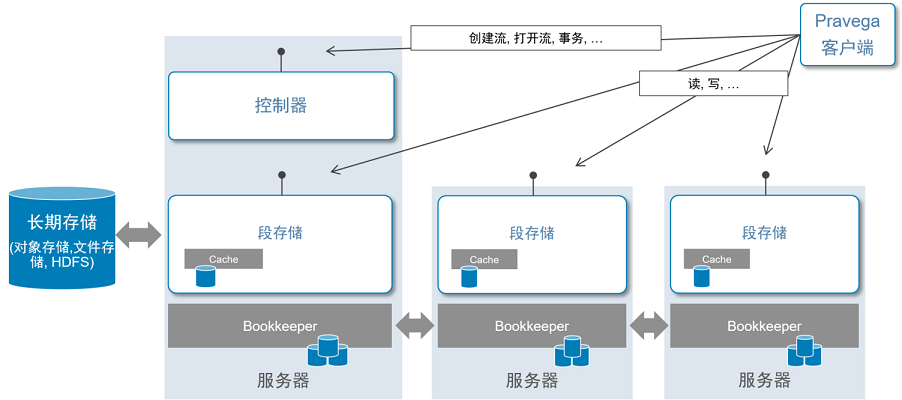
- Pravega客户端可以通过调用控制器接口管理流的创建、删除和缩放以及进行事务管理:启动事务、创建事务、跟踪事务状态;
- 所有的数据对读来说都是透明的,客户端的读写操作直接与段存储(数据面)进行交互,而不通过控制器;
- 段存储里有缓存组件保证了读写的高性能,热点数据放在bookkeeper里作为一层存储;
- 数据老化后会自动流转到长期存储(例如:对象存储系统,文件存储系统,HDFS等)里以便降低存储成本;
关键子功能 - 零接触缩放
零接触缩放:段的动态拆分与合并
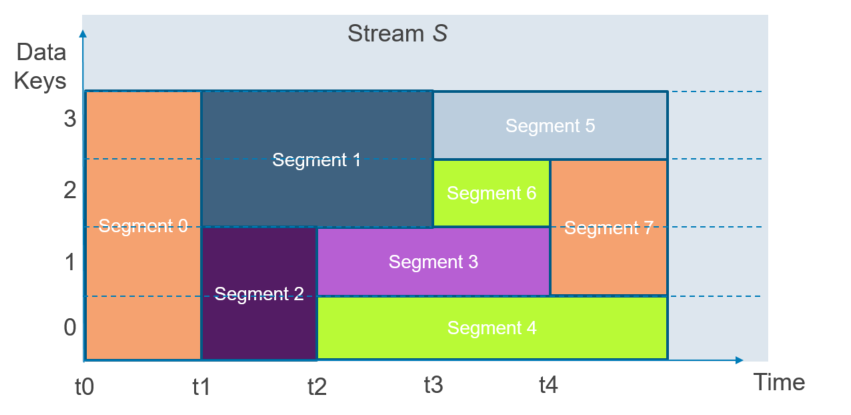
如上图所示,1)拆分:在t1时刻系统负载加大,段0被拆分成段1和段2,同时段0封装不再写入;t2时刻系统负载继续加大,段2被拆分成段3与段4,同时段2被封装不再写入;t3时刻系统负载又继续加大,段1被拆分成段5和段6,同时段1被封装不再写入;2)合并:t4时刻系统负载降低,段6与段3被合并成段7,同时段6与段3被封装不再写入。而且所有的这些行为都是Pravega里自动完成的无需人工干预。
零接触缩放:写并行 - 与Kafka比较
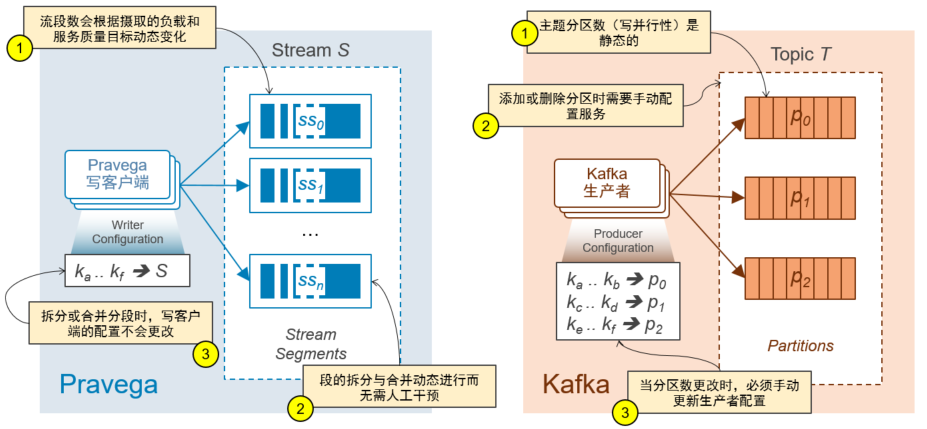
当并行写入的时候:
在Pravega里流段的数量会根据负载和服务质量目标而动态变化,并且段的拆分与合并都是自动进行的无需人工干预,同时拆分或合并流段是,写客户端的配置是静态不变的;
在Kafka里主题分区数(写并行性)是静态的,添加或删除分区时需要手动配置服务并且当分区数更改时,必须手动更新生产者配置。
零接触缩放:读并行 - 与Kafka比较
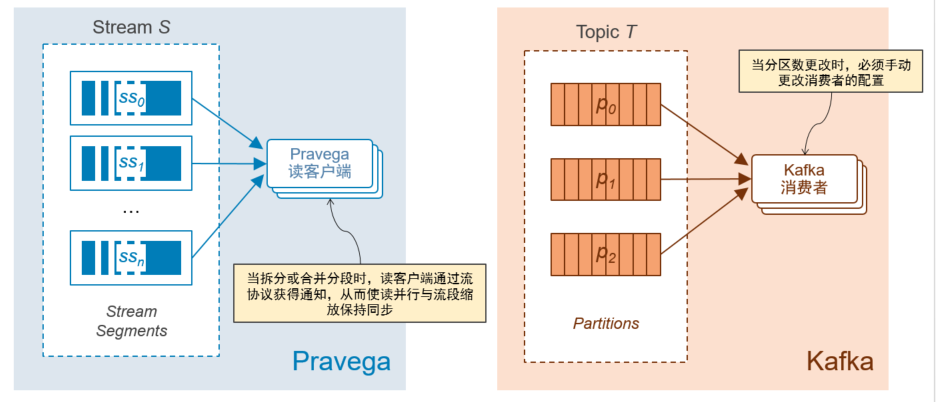
并行读取时:
- 在Pravega里,当拆分或者合并流段时,读客户端通过流协议获得通知从而使得读并行与流段缩放保持同步;
- 在Kafka里,当分区数更改时,必须手动更改使用者配置。
关键子功能 - 智能工作负载分配
智能工作负载分配 - 与Kafka比较
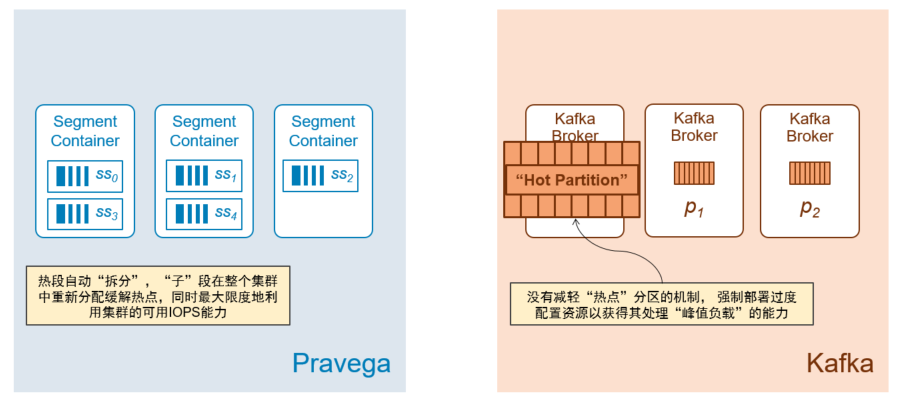
在Pravega里,热点段会自动拆分,子段在整个集群中重新分配缓解热点,同时最大限度地利用集群的可用IOPS能力;而在Kafka里没有减轻“热点”分区的机制,其强制部署并且过度配置资源以获得处理其“峰值负载”的能力。
关键子功能 - I/O路径隔离
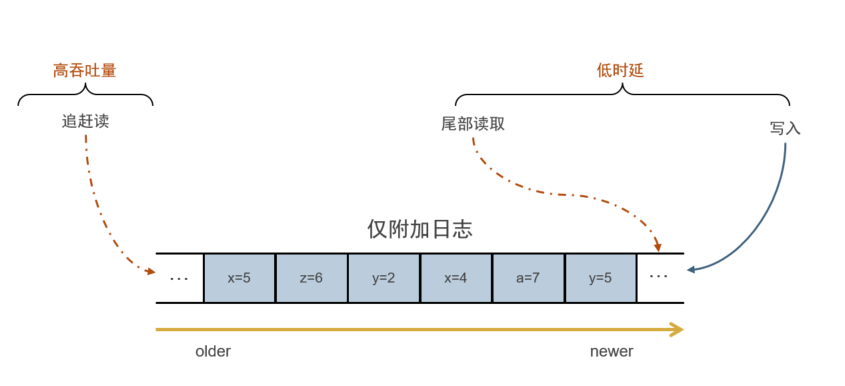
流存储的基础数据结构为仅附加写入的日志结构。考虑到高吞吐量,Pravega支持追赶读,同时为了保证低时延,Pravega还支持尾部读取以及尾部写入,从而进行了IO路径的隔离。
关键子功能 - 事务
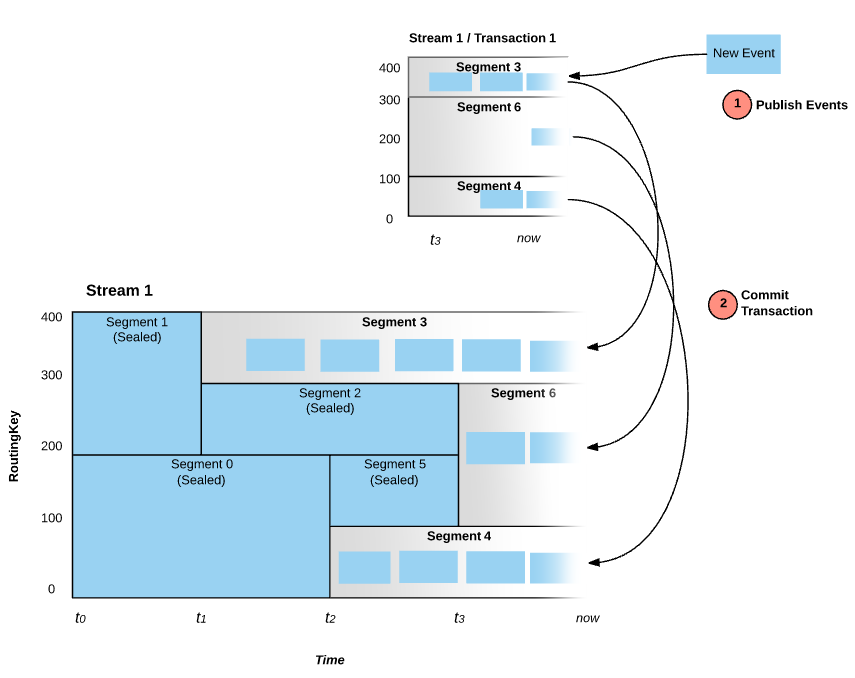
Pravega提供了事务功能,事务是写客户端可以“批处理”一堆事件并将它们作为一个处理单元原子性地提交到流中。这一堆事件要么所有都处理成功,要么所有都处理失败。在提交事务之前,发布到事务中的事件永远不会被读客户端看到。如上图所示,第一步,先将一堆事件封装在一个事务里;第二步,提交这个事务。这个事务里所有的事件要么全部都处理成功要么全部都处理失败。
总结
本文分析了物联网场景下的数据存储商业现状以及技术现状,为平衡商业成本与技术成本推出了分布式流存储系统Pravega,同时本文还介绍了流存储的特殊需求点以及与Kafka做了简要对比,此外还介绍了一些Pravega的关键架构以及一些关键特性。有关Pravega的更多详细信息,请参阅官方网站。另作者能力有限,如有不足之处欢迎留言批评指正。