开篇,马斯克们的Hyperloop
我们先来看张图,下图上部分是现在的高铁,它是跑在露天的轨道上的,下图是Elon Musk’s 在正吹的hyperloop,类似于跑在真空管道里的未来高铁。相比跑在露天轨道里的高铁,跑真空管道里的高铁好处多了:快,节能,安全,比飞机便宜。。。
技术是可以自己进化的,相信类似hyperloop的”高铁+真空管道”的模式就是未来的一种交通出行方式。
 hyperloop
hyperloop
那么HYPERLOOP跟本文又有什么关系呢? 是不是有点扯远了?其实本文讲的就是类似给高铁加上真空管道的活,二者本质上是相同的。
管道,Unix/Linux的设计哲学
在Linux或者Unix系统里,有时候我们为了查询某个信息,会输入类似如下的命令行:
1 | |
这个命令行通过“|”来分隔多个命令,前面命令的输出是紧接着的后面命令的输入,命令之间通过“|”彼此相连,并且一个命令只做一件事情。这里的“|”就是管道,把一个程序的输出和另一个程序的输入连起来的一根管子。
在Unix/Linux里存在这样的管道命令设计哲学:
- 程序是个过滤器
- 一个程序只做一件事并且做到最好
- 一个程序的输入是另外一个程序的输出
下图体现了这样的管道设计哲学,应用之间通过管道相连相互作用:
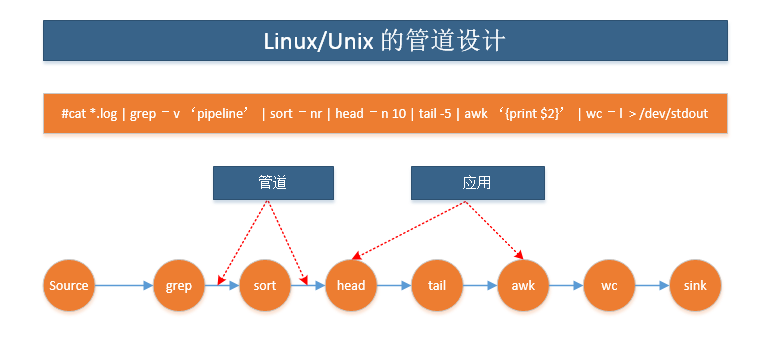 Uniux/linux pipeline
Uniux/linux pipeline
管道所要解决的问题是:高内聚,低耦合。它以一种“链”的方式将这些程序组合起来,让这些程序组成一条工作流,而每个程序又只作一件事情,给定输入,经过各个程序的先后处理,最终得到输出结果,如下图所示:
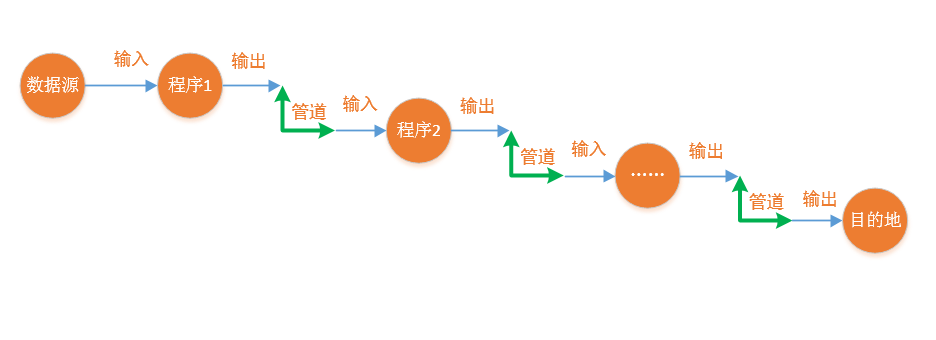 Uniux/linux pipeline
Uniux/linux pipeline
Unix/Linux在"每个程序只做一件事并且做好,每个程序的输出是对另一个程序的输入,可组合性"方面是做的非常成功的。但是,UNIX/Linux也存在一些局限性,比如:"仅单机,只支持一对一通信,无容错,仅字节流,数据处理能力有限等"。意思是说 linux/unix的这些管道命令只能在一台机器上跑,没有分布式,并且只能支持一个命令和另外一个命令之间的一对一的输入输出,无法一对多或多对一;无容错,假如管道坏了数据就出错不能恢复;只支持字节流,不支持数据格式的多样性;处理的数据量有限。
因此,我们希望可以找到一个数据处理解决方案,这个方案在保留这些Unix/linux管道的设计哲学优点的同时还能克服其缺点。 幸运的是,我们通过Flink+Pravega打造的第三代“流原生”(stream native)式的大数据处理平台实现了这种设计思想。
流原生,第三代大数据处理平台
下图体现了“流原生”(stream native)式的设计哲学,Flink是“流原生”的计算,Pravega是“流原生”的存储管道,Flink + pravega 是“流原生”的大数据处理平台。数据从pravega管道输入经过map算子计算,输出中间计算结果到pravega的管道里,数据又从pravega的管道里读入到filter算子里,再经过计算,中间结果放到了pravega管道里,再最后的计算结果经过聚合算子的计算放到了目的地的pravega的管道里。这个过程体现了算子编排和管道式编程的设计哲学。在这里pravega起了大数据处理平台里的管道的作用。
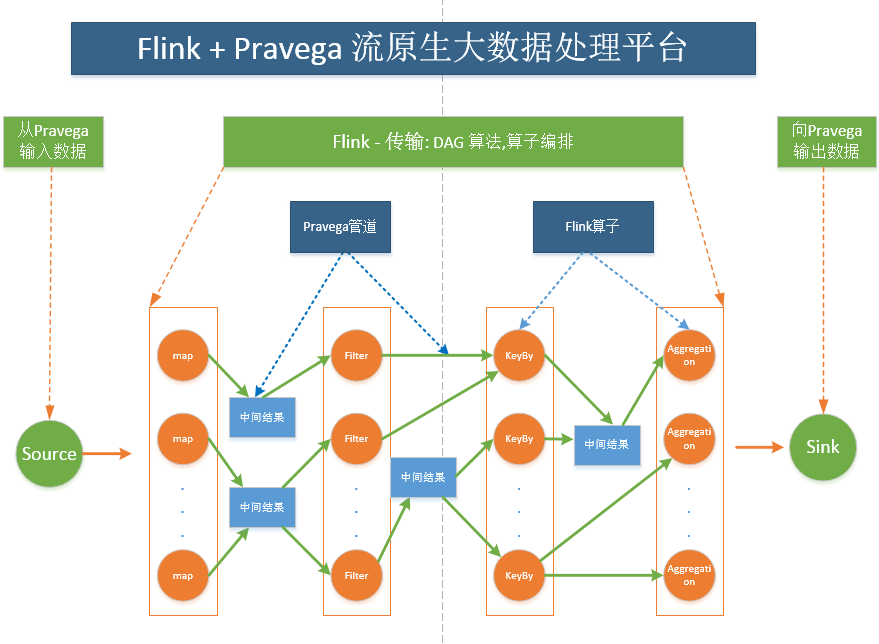 Stream processing pipeline
Stream processing pipeline
在Unix/Linux中,系统提供管道和命令,用于从一个进程到另一个进程获取字节流。
在“流原生”处理平台上,Flink提供流处理服务,pravega提供流存储服务,数据源自pravega,被Flink算子们处理后输出到pravega,这是一种将事件从一个流处理作业转移到另一个流处理作业的机制。 Flink和Pravega 所遵循的流处理平台设计哲学是:
- 每个算子都只做一件事,并且做到最好
- 每个算子的输出是另一个算子的输入
- 可组合
- 流式传输:数据是动态的,算子是静态的
- 算子可编排
- Pravega是最好的Flink搭档
- 分布式,扩展到多台机器
- 可进化的编码/解码
当前的流式处理平台一般是 Flink 加传统的存储类型,这种是”半流原生“式的大数据处理平台,计算是原生的流计算而存储却不是原生的流存储。
而Pravega就是专门给Flink们设计的原生流存储,它的数据传输方式类似于“管道”,不同于传统的块存储,文件存储以及对象存储,它是一个”管道式流存储“。
通过Flink + Pravega的组合可以实现 “流原生”(stream native)式的第三代大数据处理平台,未来已来。。。。。
思考题
最后给大家留个思考题,“流原生”(stream native)的概念有了,Flink + Pravega 也有了,而且二者的代码都是开源的(flink.apache.org, pravega.io),那么怎么把这些开源的东西产品化? 或者这个问题太伤脑筋,我们换个简单的问题:“今天中午吃什么?”
作者简介
常平,毕业于中国科学技术大学,获硕士研究生学历学位,10年+ 存储、布式系统、云计算以及大数据经验,曾就职于Marvell、AMD等,现就职于EMC,资深首席工程师,主要负责流式大数据处理平台的架构设计、编码及产品交付等。